
 Image from unsplash
Image from unsplashIn the previous article, we discussed two methods under model-free RL algorithms: policy-based and value-based. This article will focus on policy-based algorithms such as REINFORCE, Actor-Critic, and PPO methods of learning, and also implement the algorithms using simple Cart-Pole example.
Policy Gradient:
The policy gradient method aims at modeling and optimizing the policy directly. The policy is modeled with a policy function π(a|s),i.e., the probability that action a is taken at time t given the environment is in state s. We need to define a reward function as an expected return and train the algorithm to maximize the reward function. Below is the formulation of the reward function.
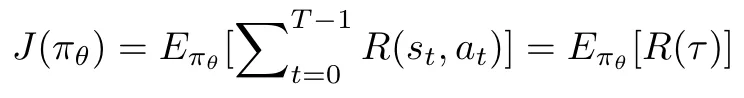
where τ represents a trajectory (sequence of states, actions, and rewards), and R(τ) is the total reward obtained in that trajectoryBelow is the simplified Policy Gradient algorithm:Loop for t=1 … T: 1. Collect an episode with policy π 2. Calculate the sum of rewards Rτ 3. Update the weight of the policy based on if positive return → increase the probability of each state-action pairs taken during episode if negative return → decrease the probability of state-action pair
REINFORCE Method:
The REINFORCE algorithm is a fundamental Policy Gradient method in Reinforcement Learning. It directly optimizes the policy by adjusting the parameters based on the rewards received during interactions with the environment. Below is the pseudo code of the REINFORCE method1. Initialize policy parameters θ, w, and learning rates 𝜶 and discounting factor γ; sample action a ~ π(a|s; θ) Reset the environment to its initial state s02. Loop for t = 1 … T: a. Sample an action at based on the policy π(at,st;θ) b. Execute the action at and get next state st+1 and reward rt+1 c. Continue until the episode terminates3. Calculate the total return Gt from each time step t.4. Update the policy for each time step θ ← θ + 𝜶∇θ loge πθ(at|st)Gt5. repeat the above steps for multiple episodes until the policy converges
Implementation of REINFORCE
We will now take the CartPole example and train the agent to balance the pole using the REINFORCE method. The system consists of a cart that can move left or right on a 1D track and a pole attached to it via a hinge. The goal is to balance the pole by applying forces to move the cart. If the pole tilts beyond a certain angle or the cart moves too far from the center, the episode ends, and the agent receives a penalty.Let’s start by creating the CartPole environment using openai’s gym library. We extract two main parameters from the environment, state_size and action_size, and discount factor (gamma) that control how much we value future rewards versus immediate rewards.This import of environment will be the same throughout the algorithms.import numpy as npimport torchimport torch.nn as nnimport torch.optim as optimfrom torch.nn import functional as Fimport gym# Create the environmentenv = gym.make("CartPole-v1")# Get the state and action sizesstate_size = env.observation_space.shape[0]action_size = env.action_space.ngamma = 0.99 # discount factorHere we define the policy network using pytorch. The network is a simple feedforward neural network with two layers, the final output is a softmax layer to get the probability distribution of each action. This policy network learns the mapping of state to actions.# Define the policy function, and its optimizer class Policy(nn.Module): def __init__(self): super(Policy, self).__init__() self.fc1 = nn.Linear(state_size, 32) self.fc2 = nn.Linear(32, action_size) def forward(self, x): x = torch.relu(self.fc1(x)) x = self.fc2(x) return torch.softmax(x, dim=-1)policy = Policy()optimizer = optim.Adam(policy.parameters(), lr=1.4e-3)We run the training for 1000 episodes, and in each episode, agents interact with the environment, take an action, and get a reward. This loop continues until agents lose or stop after reaching a certain score. After the run ends, we compute the discounted reward for each time step, then compute the policy loss by multiplying log-probabilities of actions with the discounted reward and backpropagate this lossepi_score = []for episode in range(1000): state, _ = env.reset() done = False log_probs = [] rewards = [] while not done: # Select action state = torch.tensor(state, dtype=torch.float32).reshape(1, -1) probs = policy(state) action = torch.multinomial(probs, 1).item() log_prob = torch.log(probs[:, action]) # Take step next_state, r, done, trunc, _ = env.step(action) done = done or trunc rewards.append(r) log_probs.append(log_prob) state = next_state # Update policy discounted_rewards = np.zeros_like(rewards) for j in reversed(range(len(rewards))): discounted_rewards[j] = rewards[j] + (discounted_rewards[j+1]*gamma if j+1 < len(rewards) else 0) discounted_rewards = torch.tensor(discounted_rewards) # Normalize rewards discounted_rewards = (discounted_rewards - discounted_rewards.mean()) /(discounted_rewards.std() + 1e-9) # Policy gradient update policy_loss = -torch.cat(log_probs) * discounted_rewards policy_loss = policy_loss.sum() optimizer.zero_grad() policy_loss.backward() optimizer.step() epi_score.append(sum(rewards)) print("Run episode{} with rewards {}".format(episode, np.sum(rewards)), end="\r")

Actor-Critic Method:
The Actor-Critic architecture is a dual-component framework that combines an Actor, which models the policy mapping from states to actions, and a Critic, which estimates the value function and provides feedback on the Actor’s performance.Actor-Critic method consists of two models, which may or may not share parameters:
- Actor/Policy Network: The actor network is responsible for taking action for a given state of the environment. It learns the policy π(s|a;w) and updates the policy function parameters w
- Critic/Value Network: The critic evaluates the actions taken by the actor. It estimates the value function V(s), which is the expected cumulative future reward starting from state 𝑠. The critic helps guide the actor by providing a measure of how good or bad an action was in terms of expected reward
The following are the steps in the actor-critic algorithm1. Initialize parameters s, θ, w, and learning rates 𝜶θ (policy lr) and 𝜶w (value function lr); sample action a ~ π(a|s; θ)2. Loop for t = 1 … T: 1. Sample reward ri ~ R(s,a) and next state s' ~ P(s' | s,a) 2. Then sample the next action a' ~ π(s', a'; θ) 3. Update policy parameters: θ ← θ + 𝜶θQ(s,a;w)∇θ logeπ(a|s;θ) 4. Compute the correction for action-values at time t: Gt:t+1 = rt + 𝜸Q(s',a';w) - Q(s,a;w) and use it to update value function parameters w ← w + 𝜶wGt:t+1∇w Q(s,a;w) 5. Update a ← a' and s ← s'
 Actor Critic Network Framework
Actor Critic Network FrameworkNow let’s take the same CartPole example and train it using the actor-critic methodWe will use the same import of environments as used in the REINFORCE methodAfter setting the environment, we will create the Actor and Critic network using a feedforward neural network, and each network will be optimized separately. Cross entropy loss is used to optimize the policy network and MSE loss will be used to optimize the critic network# Defining Actor and Critic Networks, and their optimizersclass ActorNet(nn.Module): def __init__(self, state_size, actions_size): super(ActorNet, self).__init__() self.fc1 = nn.Linear(state_size, 32) self.fc2 = nn.Linear(32, action_size) def forward(self, x): x = torch.relu(self.fc1(x)) x = self.fc2(x) return x class CriticNet(nn.Module): def __init__(self, state_size, actions_size): super(CriticNet, self).__init__() self.fc1 = nn.Linear(state_size, 32) self.fc2 = nn.Linear(32, 1) def forward(self, x): x = torch.relu(self.fc1(x)) value = self.fc2(x) return value# Initialize actor-critic network and optimizeractor_func = ActorNet(state_size,action_size)critic_func = CriticNet(state_size,action_size)opt1 = torch.optim.AdamW(critic_func.parameters(), lr=1.4e-3)opt2 = torch.optim.AdamW(actor_func.parameters(), lr=1.4e-3)cross_entropy = nn.CrossEntropyLoss(reduction="none")mse_loss = nn.MSELoss(reduction="none")Creating a function to choose an action based on the policy probabilities.# Choosing an action based on the policy probabilitiesdef select_action(network, state): state = torch.from_numpy(state).float().unsqueeze(0) logits = network(state) logits = logits.squeeze(dim=0) action_probs = F.softmax(logits, dim=-1) action = torch.multinomial(action_probs, 1).item() return action
Training Loop
For each episode, we let the agent interact with the environment and store all the states that it has encountered, each action that is taken, and the rewards obtained for each action. It continues till the episode ends, meaning either the pole has fallen or it has reached the score limit.epi_score = []for i in range(1000): done = False states = [] actions = [] rewards = [] s, _ = env.reset() while not done: states.append(s.tolist()) a = select_action(actor_func,s) s, r, term, trunc, _ = env.step(a) done = term or trunc actions.append(a) rewards.append(r)Discounted rewards are calculated for the rewards using the discounting factor γ. # Calculate the discounted reward discounted_rewards = np.zeros_like(rewards) for j in reversed(range(len(rewards))): discounted_rewards[j] = rewards[j] + (discounted_rewards[j+1]*gamma if j+1 < len(rewards) else 0)Here we compute the critic loss by taking MSE between the predicted score from the critic network and the actual discounted rewards(scored), perform backpropagation, and update the critic network. # Optimize value loss (Critic) opt1.zero_grad() states = torch.tensor(states, dtype=torch.float) discounted_rewards = torch.tensor(discounted_rewards, dtype=torch.float) values = critic_func(states) values = values.squeeze(dim=1) vf_loss = mse_loss(values,discounted_rewards) vf_loss.sum().backward() opt1.step()We calculate the advantage by taking the difference between the discounted reward and the estimated values from critic network. Cross entropy loss is used to compute the log probabilities of the actions, and is scaled to the advantage. The actions that led to higher rewards get their probabilities increased. # Optimize policy loss (Actor) with torch.no_grad(): values = critic_func(states) opt2.zero_grad() actions = torch.tensor(actions, dtype=torch.int64) advantages = discounted_rewards - values logits = actor_func(states) log_probs = -cross_entropy(logits, actions) pi_loss = -log_probs * advantages pi_loss.sum().backward() opt2.step() epi_score.append(sum(rewards)) print("Run episode{} with rewards {}".format(i, np.sum(rewards)), end="\r")

Proximal Policy Optimization(PPO) Method:
PPO directly optimizes the policy to maximize the expected reward by improving the policy iteratively. One of the key features of PPO is that it uses a “proximal” objective function, which means that it only updates the policy network in a small region around the current policy. This helps to prevent the algorithm from making large, unstable updates that could harm the performance. There are two methods to prevent large updates, PPO-Penalty and PPO-Clip. In this article, we’ll learn about PPO-Penalty in this article. In PPO-Penalty, Kullback-Leibler (KL) divergence between the new and old policies is taken to penalize the objective function.The objective function of PPO-Penalty is given by

Let’s use the cart-pole example to train with the PPO-Penatly method.We will use the same Imports from REINFORCE methods and the same actor and critic networks from the Actor-Critic algorithm with loss function.We can combine Actor and Critic parameters to create a single optimizer. Therefore, we will apply a weightage(value_w) to the value loss while calculating the total lossall_params = list(actor_func.parameters()) + list(critic_func.parameters())opt = torch.optim.AdamW(all_params, lr=1e-3)kl_beta = 0.20 # Penalty coefficient for KL-divergencevalue_w = 0.50 # weightage of critic/value lossCreating a function to calculate the logits, action probabilities and its actions.# Pick up action and following properties for state (s)def pick_sample_and_logp(s): with torch.no_grad(): s_batch = np.expand_dims(s, axis=0) s_batch = torch.tensor(s_batch, dtype=torch.float) # Get logits from state logits = actor_func(s_batch) logits = logits.squeeze(dim=0) # From logits to probabilities probs = F.softmax(logits, dim=-1) # Pick up action's sample a = torch.multinomial(probs, num_samples=1) a = a.squeeze(dim=0) # Calculate log probability logprb = -F.cross_entropy(logits, a, reduction="none") return a.tolist(), logits.tolist(), logprb.tolist()
For Loop
Initialize the variables to track the trajectories taken by the agent. Run the environment, let the agent make decisions, and store the actions and their logits taken at each step along with the reward obtained. The environment will continue running until the pole falls or reaches its maximum score.epi_score = []for i in range(1000): done = False states = [] actions = [] logits = [] logprbs = [] rewards = [] s, _ = env.reset() while not done: states.append(s.tolist()) a, l, p = pick_sample_and_logp(s) s, r, term, trunc, _ = env.step(a) done = term or trunc actions.append(a) logits.append(l) logprbs.append(p) rewards.append(r)Calculate the cumulative or discounted reward with the discounting factor γ. # Get cumulative rewards cum_rewards = np.zeros_like(rewards) for j in reversed(range(len(rewards))): cum_rewards[j] = rewards[j] + (cum_rewards[j+1]*gamma if j+1 < len(rewards) else 0)Converting all the stored trajectories into tensor # Convert to tensor states = torch.tensor(states, dtype=torch.float) actions = torch.tensor(actions, dtype=torch.int64) logits_old = torch.tensor(logits, dtype=torch.float) logprbs = torch.tensor(logprbs, dtype=torch.float) logprbs = logprbs.unsqueeze(dim=1) cum_rewards = torch.tensor(cum_rewards, dtype=torch.float) cum_rewards = cum_rewards.unsqueeze(dim=1)Passing the states to get updated values and action logits, and determine the advantage and policy prob ratios, this will give us how much the policy has changed. opt.zero_grad() values_new = critic_func(states) logits_new = actor_func(states) # Get advantages advantages = cum_rewards - values_new advantages = (advantages - advantages.mean()) / advantages.std() # Calculate P_new / P_old logprbs_new = -cross_entropy(logits_new, actions) logprbs_new = logprbs_new.unsqueeze(dim=1) prob_ratio = torch.exp(logprbs_new - logprbs)Calculating the KL divergence between old and new policies probability distribution. It will ensure that the new policy does not deviate too much from the old policy # Calculate KL-Div l0 = logits_old - torch.amax(logits_old, dim=1, keepdim=True) l1 = logits_new - torch.amax(logits_new, dim=1, keepdim=True) e0 = torch.exp(l0) e1 = torch.exp(l1) e_sum0 = torch.sum(e0, dim=1, keepdim=True) e_sum1 = torch.sum(e1, dim=1, keepdim=True) p0 = e0 / e_sum0 kl = torch.sum(p0 * (l0 - torch.log(e_sum0) - l1 + torch.log(e_sum1)),dim=1,keepdim=True)Calculate the total loss and backpropagate the loss and update both actor and critic parameters. # Critic loss vf_loss = mse_loss(values_new, cum_rewards) # Calculating total loss loss = -advantages * prob_ratio + kl * kl_beta + vf_loss * value_w # Optimizer loss.sum().backward() opt.step() epi_score.append(sum(rewards)) print("Run episode{} with rewards {}".format(i, np.sum(rewards)), end="\r")
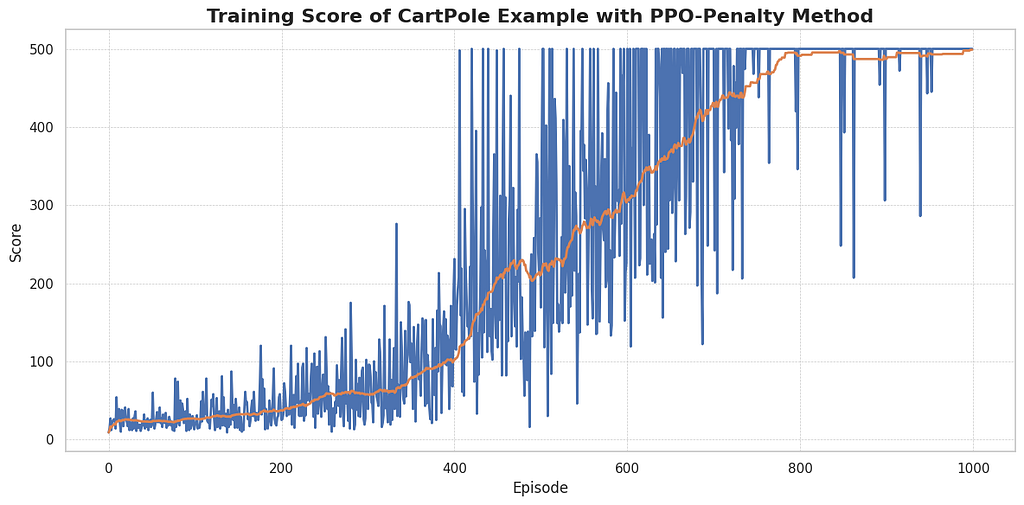
Summary
REINFORCE is a simple algorithm but suffers from high variance, making it slow for complex tasks. In Actor-Critic, adding a value function as a baseline improves the learning efficiency but this baseline can introduce bias. PPO-Penalty has a balance between efficient updates and exhibits more stable learning progression due to its conservative update strategy, which limits the large policy updates with the KL divergence penalty term. There is no single best algorithm for all RL problems. It is important to analyze and compare different algorithms depending on the scenario.
References:
https://github.com/tsmatz/reinforcement-learning-tutorials/tree/masterh…
A Hands-On Guide to Policy Gradient Algorithms for Beginners - REINFORCE, A2C, PPO was originally published in Tata 1mg Technology on Medium, where people are continuing the conversation by highlighting and responding to this story.
- Log in to post comments