
In this article, we will go through the basics of reinforcement learning focusing on the framework of RL, some of the key concepts like Markov Decision Process, and Bellman Equations which forms the mathematical foundation of RL. We will also see different RL algorithms and the challenges that we face in RL.
What is Reinforcement Learning?
Imagine teaching a computer program to drive a car. Instead of providing it with a set of rules or examples, reinforcement learning lets the program learn by doing. It tries different things and experiences the consequences (like crashing or staying on the track), and adjusts its behavior accordingly. The goal is to make good decisions under uncertainty, which in this case is staying on track all the time. Over time, the program becomes better at navigating the track. This interactive and experimental approach makes RL an interesting field of machine learning.
Reinforcement learning involves learning, optimization, delayed consequences, generalization and exploration. Goal is to learn to make good decisions under uncertainty
Examples of RL used in Real World
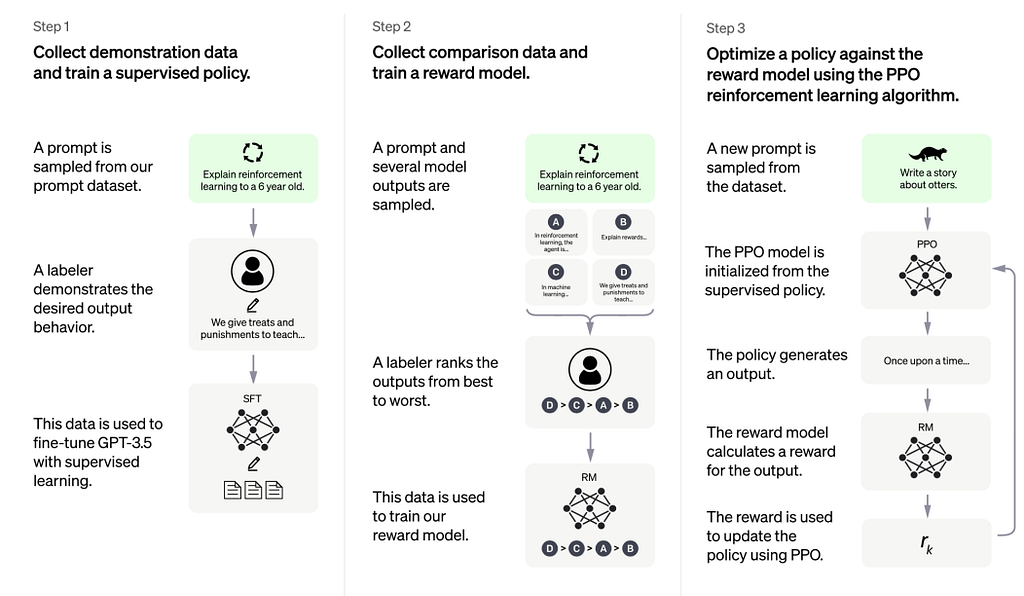
In ChatGPT, after being trained on massive amounts of text data, the model is further refined through a process called Reinforcement Learning with Human Feedback (RLHF). Human experts rank different AI-generated responses, providing the model with valuable feedback. By learning from these rankings, ChatGPT gradually improves its ability to generate helpful, informative, and engaging conversations.
Deepmind created an RL agent that beat the world’s top Go player, it took reinforcement learning to a whole new level. It learned by playing countless games against itself, figuring out winning strategies through trial and error. Each successful move earned AlphaGo points, motivating it to improve. It can analyze the board, evaluate potential moves, and predict the long-term consequences of each action, all while considering the complex strategies and tactics involved in the game
The RL Framework
Let’s look at the different components of reinforcement learning. In solving an RL problem such as learning to drive a car on the race track (in the above example), we can model the problem as a Markov Decision Process (MDP) usually consisting of the following components.
- Agent: The agent is the program or an algorithm learning to drive the car. Its goal is to learn the best way to navigate the track. This is the decision-maker in the RL system. It interacts with the environment and learns through trial and error.
- Environment: The driving track, along with all its features like curves, other cars, and edges forms the environment that the agent interacts with. The environment is the world that the agent lives in and interacts with, it provides the agent with states, rewards, and penalties.
- State (s): At any point in time, the state represents the current situation of the car on the track — its position, speed, proximity to the edge, and other relevant information like the distance to the next turn. Representation of the environment at any particular point in time provides the agent with information to make a decision.
- Action (a): An action is a set of possible moves or decisions the agent can take such as accelerating, braking, steering left or right. These decisions affect the car’s behavior on the track and can affect the state of the environment
- Reward (r): A numerical feedback signal from the environment after taking an action, which indicates the immediate benefit or cost. For example, if the car stays on track, it gets a positive reward. If it crashes, the agent receives a negative reward. The goal is to maximize cumulative rewards, meaning it learns to take actions that keep it on track for longer
- Policy (π): This is a strategy that an agent uses to decide its action based on the current state. It is a mapping from states to actions. It defines the agent’s behavior in different situations. For example, The policy helps the car choose whether to accelerate when it is on a straight path, slow down if it is approaching a curve, or turn near the edge or curve, based on its current state. A good policy would allow the car to complete the lap as efficiently as possible, balancing speed with safety.
The agent and environment interact at each of a sequence of discrete time steps t, at each time step, agent receives some representation of the environment state St and on that basis agent selects an action At. One step later as a consequence of its action, the agent receives a reward Rt+1 and finds itself in a new state St+1. The Markov Decision Process and agent together give rise to a sequence of trajectory as followsS0, A0, R1, S1, A1, R2, S2, A2, R3,… St, At, Rt

Key Concepts in RL
State Transition Probability:
In a finite MDP, the environment has a limited number of states S, actions A, and possible rewards R. This means that the probability of transitioning from one state to another and receiving a particular reward at a given time depends solely on the current state and the chosen actionP(s’| s, a) = P{St+1 = s’ | St = s, At = a}Where, s’, s => S, r => R and a => A. The function p defines the dynamics of MDPThe state transition probability function P(s’ | s, a) defines the probability of moving from state s to s′ when the agent takes action a
Reward:
The reward function R(s,a) provides the immediate reward received after the agent takes action a in state s.R(s,a) = E[ rt | St=s, At=a ]This gives the expected reward rt at time t, conditioned on being in state s and taking action a.The agent’s goal is to maximize the cumulative reward over time t and some actions can have delayed consequences that the agent must learn to account for both immediate and future rewards. This cumulative discounted reward is the agent received from time t is known as return Gt given by:
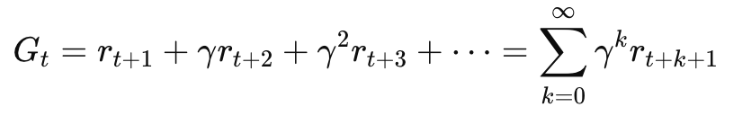
Here the discount factor γ (where 0 ≤ γ ≤1) controls the importance of future rewards. When γ=0, the agent only cares about immediate rewards, while when γ=1, it values future rewards equally.
Policy:
A policy π(a|s) defines the behavior of the agent, representing the probability of selecting action a when in state sFor deterministic policies, π is a function maps states to actionsFor stochastic policies, π(a|s) is a probability distribution over actions given a state
Value Function:
It is important to understand the following two functions, as these form the basis of different RL algorithms such as DQN and Actor-Critic methods. The value function measures the expected return from a given state under a particular policy. There are two main types of value functions:State Value Function: Vπ(s): This function indicates the desirability of being in a specific state, considering the potential future rewards from that position.
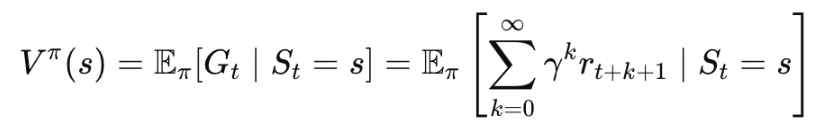
Action Value Function: Qπ(s,a): This function represents the desirability of taking a specific action in a given state. It takes into account the potential rewards that can be obtained if action a is chosen and then the optimal policy is followed.
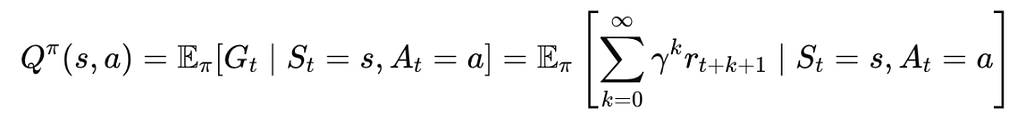
Bellman Equation: A fundamental property of value functions used throughout reinforcement learning is that they satisfy recursive relationships. For any policy π and any state s, the following consistency condition holds between the value of s and the value of its possible successor states
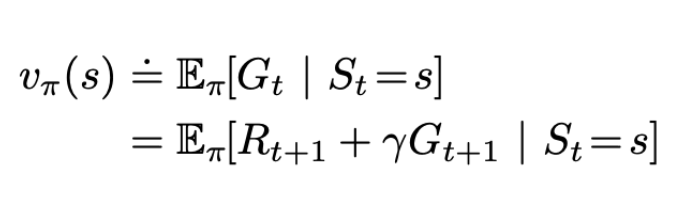
In simple terms, it can also be written as
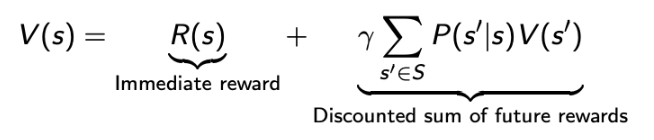
We can also express the Bellman equation using matricesV = R + γPV
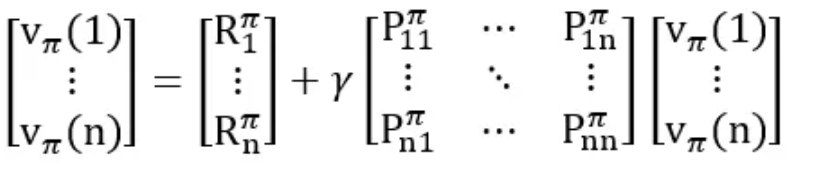
Types of Reinforcement Learning Algorithms:
- Model-Based RL: in this approach, the agent learns the model of the environment and uses it to simulate future states and reward, allowing it to plan ahead
- Model-Free RL: The agent directly learns the optimal policy by interacting with the environment without creating a model of the environment explicitly. This method is further classified into:- Value-Based Methods: This method involves learning the value function and selecting actions that maximize the expected returnExample: Consider a car navigating a maze to reach a destination. In value-based methods, the car estimates the value of each potential route at an intersection. It calculates which route is more likely to lead to a successful journey (higher value), and then takes that route - Policy-Based Methods: In this case, the agent learns the policy directly i.e., it focuses on learning the best action to take in a given state without estimating the value of those actions. It optimizes the policy by maximizing the expected returnExample: Imagine training a robot to walk. With policy-based methods, the robot learns a mapping from its current position to the next best movement (action). It doesn’t worry about evaluating each possible action; instead, it continuously adjusts its walking policy (how it moves its legs) to walk more smoothly over time

On-Policy and Off-Policy Methods of Learning:
On-Policy and Off-Policy are two key approaches within model-free learning. They are differentiated by how they handle the relationship between the behavior policy used for exploration and the target policy that is being optimized.On-Policy Method: On-policy methods evaluate and improve the policy that is currently being used by the agent. Here, the agent updates its policy based on the actions it takes and the rewards it receives while following the same policy. This creates a direct relationship between exploration and policy improvement, ensuring that the agent learns from its actual experiences.Off-Policy Method: Off-policy separates the learning process into two policies: the behavior policy used for exploration and the target policy for optimizing. The agent learns about the optimal target policy from the experiences gathered by the behavior policy, even though it may not follow this policy itself. This separation allows off-policy methods to be more flexible and sample-efficient.
On-policy learning: “Learn on the job”; Learn about policy π from experience sampled from π Off-policy learning: “Look over someone’s shoulder”; Learn about policy π from experience sampled from policy µ
Popular Reinforcement Learning Algorithms
- Deep Q-Networks (DQN): DQN combines Q-learning with deep neural networks, allowing agents to learn policies from high-dimensional inputs like images. DQN was famously used in training AI agents to play Atari games directly from pixel inputs, achieving human-level performance. The key innovation in DQN is the use of a replay buffer, which stores past experiences to break the correlation between consecutive samples and improve learning stability.
- Policy Gradient Methods: Policy gradient methods directly optimize the policy by adjusting its parameters in the direction that maximizes the expected return. The REINFORCE algorithm is one of the simplest policy gradient methods and updates the policy by following the gradient of the expected reward. Policy gradient methods are particularly useful in environments with continuous action spaces, where value-based methods may struggle.
- Actor-Critic Algorithms: Actor-Critic methods combine the advantages of value-based and policy-based approaches. They consist of two components:- The Actor learns the policy- The Critic estimates the value functionBy using the critic to guide the actor’s updates, actor-critic methods can reduce the variance of policy gradient estimates and lead to more stable learning.
Challenges in Reinforcement Learning:
- State Representation Dependence: Reinforcement learning(RL) algorithms are very dependent on accurate state representations. The quality of the state information provided to the agent significantly impacts its ability to learn and make effective decisions. If the state representation is incomplete, noisy, or misleading, the agent may struggle to identify optimal policies and achieve desired outcomes.
- Reward Design: Defining appropriate reward functions is critical to the success of RL algorithms. Poorly designed rewards can lead to unintended behavior, as agents may exploit loopholes in the reward system.
- Exploration & Exploitation trade-off: Exploration involves trying new actions to discover their potential rewards, while exploitation means choosing the best-known action to maximize rewards. Balancing these two is crucial in RL. Over-exploration can lead to slow learning, while over-exploitation might cause the agent to get stuck in suboptimal behavior without discovering better strategies.
- Sample Inefficiency: RL algorithms often require a large number of interactions with the environment to learn effective policies. This can be particularly costly in real-world scenarios where each interaction may involve physical resources (like in robotics) or human input (as in chatbots), making RL sample-inefficient compared to other machine-learning methods.
- Credit Assignment Problem: It refers to the challenge of determining which sequence of actions contributed to a certain outcome, especially when the reward is delayed. The reward may come several steps after the action that contributed to it. This makes it difficult to assign credit to the right action making it difficult to build an effective policy. For example, in a video game, when an agent gets win or lose only at the end of the game, but throughout the play it takes many decisions to achieve that outcome.
- Transfer Learning and Generalization: RL agents often struggle with transferring knowledge from one task to another. They may overfit to the specific environment they are trained in and fail to generalize to new or slightly different environments. Finding ways to enable RL agents to generalize well and transfer learned skills between tasks is an ongoing area of research
Summary
In this article, we went through the basics of Reinforcement Learning and its key components, including Bellman equation, value function and policy function. We explored how these approaches work to improve decision-making in environments and discussed on-policy and off-policy methods. In the next article, we will look deeper into policy-based algorithms, with focus on Policy Gradient, REINFORCE method, and Actor-Critic methods with some examples.
References
Here’s a list of some useful resources that we referred to during the ideation of this article:
- Book on Reinforcement Learning
- A Succinct Summary of Reinforcement Learning
- Reinforcement Learning Lecturing Materials
- Understanding On and Off Policy Methods
- RL Framework from Hugging Face
Reinforcement Learning 101: A Quick Start Guide was originally published in Tata 1mg Technology on Medium, where people are continuing the conversation by highlighting and responding to this story.
- Log in to post comments