
How we handled database CPU spike at 1mg?
Being a part of the fast moving startup culture, Tata 1mg takes it upon itself in providing the quickest response to your problems. While medicines or health products remain critical in times like these, our systems have to be quick in finding answers to your questions and results to your searches. As a tech team, we are always on our toes to solve problems that can cause a delay in our customer experience.On one such occasion, we stumbled upon an unusual spike in our Database CPU time (DB CPU), which started to occur at every Nth interval. On a regular day, the cpu time stays below 20%. We observed a sudden surge that increased the CPU time to a whopping 60–70%, with no apparent reason.To explain in simpler terms: Imagine you’ve visited a pharmacist and inquired about an oximeter. He gets back to you with one but you’re still thinking if it’s a good buy, so you ask him for an opinion. He then opens his big book of customer feedback and looks for answers. Browsing through one page at a time, he finally finds the top 10 customer reviews about this device and hands them over to you, so you can make a better decision. At Tata 1mg, we make sure this entire process only takes a few microseconds. The process of screening through 100s of reviews of any product and to present the top 10 shouldn’t take more than a fraction of a second.Back to the issue:As a ground in routine, my first and obvious response was to check the slow logs and I was lucky enough to find the query that was causing the spike. It was being run through a scheduled job, which justified the periodical behaviour.Well, the Culprit:select distinct t_top.id, t_outer.rateable_id, t_top.rateable_type, t_top.rank_scorefrom ratings t_outer join lateral ( select * from ratings t_inner where t_inner.rateable_id = t_outer.rateable_id order by t_inner.rank_score desc, t_inner.id limit 10) t_top on truewhere t_outer.rateable_id IN (1,2,3...300000)order by t_outer.rateable_id, t_top.rank_score desc, t_top.id;What’s going on? 😩. Let’s dig in a bit and understand the issue!
What is a Lateral Join?
Introduced in Postgres 9.3Technically speaking, aLATERAL join is more like a correlated subquery, not a plain subquery. Expressions to the right of a LATERAL join are evaluated once for each row left of it - just like a correlated subquery - while a plain subquery is evaluated once only.In simpler terms, while a plain subquery is evaluated only a single time, a correlated subquery like a lateral join is evaluated multiple times.
To know more:
https://stackoverflow.com/questions/28550679/what-is-the-difference-bet…
Assessing the problem:
The Query referred above is fetching the Top 10 reviews for each of the rateable id passed to it.The expression on left to the LATERAL join has a where clause, which consists of around 30K ids to match with.where t_outer.rateable_id IN (1,2,3...300000)The expression right to the LATERAL join is being evaluated once for each of the id, which means ~30K sub-queries are being fired. Here is the sub-query:select * from ratings t_innerwhere t_inner.rateable_id = t_outer.rateable_idorder by t_inner.rank_score desc, t_inner.idlimit 10It seems to be of O(n) complexity, as the number of sub-queries are directly proportional to the number of ids.

The Query as a whole took ~60 seconds to complete. That’s massive 😳!
ROW_NUMBER():
Introduced in Postgres 8.4

The ROW_NUMBER() function is a window function that assigns a sequential integer to each row in a result set. The following illustrates the syntax of the ROW_NUMBER() function:ROW_NUMBER() OVER( [PARTITION BY column_1, column_2,…] [ORDER BY column_3, column_4, …])The set of rows on which the ROW_NUMBER() function operates is called a window.The PARTITION BY clause divides the window into smaller sets or partitions. If you specify the PARTITION BY clause, the row number for each partition starts with one and increments by one.
Because the PARTITION BY clause is optional to the ROW_NUMBER() function, therefore you can omit it, and ROW_NUMBER() function will treat the whole window as a partition.
The ORDER BY clause inside the OVER clause determines the order in which the numbers are assigned.
Revised Query:
SELECT * FROM ( SELECT *, ROW_NUMBER() OVER (PARTITION BY rateable_id) AS row FROM ( SELECT id, rateable_id, rateable_type, rank_score FROM ratings where rateable_id IN (1,2,3...30000) order by rateable_id, rank_score desc, id ) x) y WHERE y.row <= 10;Now, that looks Elegant 🤩!We are partitioning the window into sub-windows on the basis of rateable_id and the records in each window are assigned a row number in the order specified by the order clause, followed by a simple filtering where row number is less than 10 and that’s it.
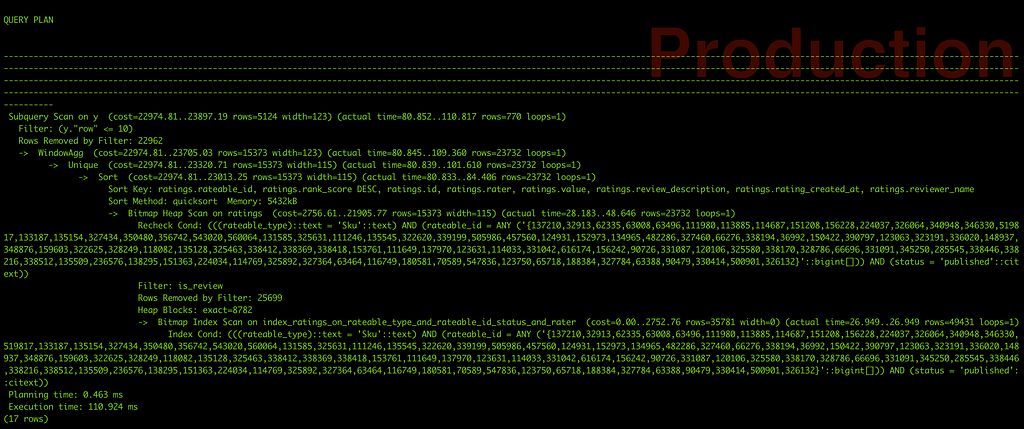
Here we are, all the way from O(n) to O(1).
Showcasing an improvement by 600%, the Query time reduced massively from ~60 seconds to ~100ms.
This was unbelievable!! I obviously double checked the revised query in terms of correctness of results 😄.I am sure, you too are super excited to see the actual impact on the cpu Utilisation. Here we go:
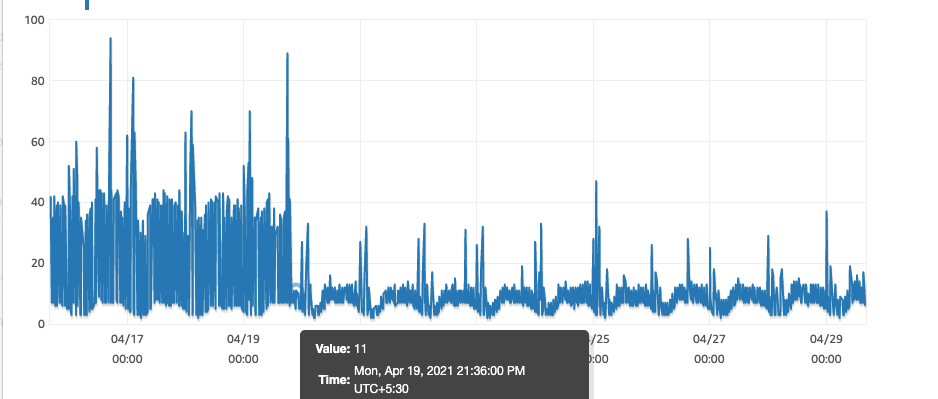 RDS cpu Utilisation
RDS cpu UtilisationAs the graph shows we noticed a reduction in cpu by ~30%, which is a giant leap for us.Hope you enjoyed it as much as I did while penning it down.Thank you for reading!! Have a Good Day 😊.
Decoding a surge in Query time: From 60seconds to 100ms was originally published in Tata 1mg Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.
- Log in to post comments