
& how 1mg is solving this
 https://www.andersondiagnostics.com/pathology/
https://www.andersondiagnostics.com/pathology/Imagine yourself at a doctor’s clinic. You, carrying a stack of papers constituting Lab Reports, Prescriptions, etc. The doctor asks you for some Lab Report & you start juggling with that stack. Next, he asks for some other Lab Parameter & again, the search begins, leafing through pages. Now, imagine a situation where you have a stack full of documents!
Life looks painful, Right?
In this digital era, where digitization has reached almost every other domain, this space still operates in a manual fashion mostly where a patient maintains a file with multiple Lab Reports & prescriptions as papers, carrying them with him whenever he/she needs to see a doctor. This though leads to a number of issues that are rarely discussed.
- Patients, mostly, don’t understand their health records especially Lab Reports
- Any Lab Report is a rich source of information that can unlock new horizons in healthcare. Hence, shouldn’t be left undigitized
Hence, understanding the importance of this problem, Digitization of Lab Reports has been amongst the most prominent domains the Data Science team at 1mg has been working for. By Lab Report Digitization, we mean extracting important information i.e Lab Parameters & value mapped against it in hard/soft copies of Lab reports.Can digitizing Lab Reports help a patient or doctor in any way? In many ways as mentioned below:
- A holistic understanding of Lab Reports
What does a particular parameter mean?
Which organ system does it affect?
- No need to maintain a stack of hard copies
- Time savings for doctors.
Doctors won’t need to manually ask questions
No more searching through hard copies about past health records of a patient
- AI-based insights & advise will boost a better general health
Disease you might be at verge of
Suggesting suitable diet to keep things under control
Summarizing reports so as to save time
The following sections describe the process built to be able to achieve high quality 100% machine dependant diagnostics report digitization system. Eventually, we aim to build a digitization service that can extract standardized parameters from even the largest of PDF reports in under a minute!Cool eh!! 😎

Initial Challenges
At the outset, we knew we would face certain challenges while we attempt to solve the problem of undigitised PDF reports.
- Huge Variety of Lab Reports: As 1mg partners with many Labs & each partner offers multiple tests, there is heavy diversity in lab report formats.
- No Manual Validation Possible Over the years, millions of patient reports have been lying as PDFs. To digitise them would mean building validations and checks into the system during digitisation. Verifying the extracted data is a tough task!
- Need for Standardisation Different labs use different nomenclature for parameter names, for example, Glucose Fasting, Fasting Blood Glucose, Glucose-F, Fasting Glucose, Mean Glucose Fasting. Digitisation without standardisation won’t make sense.
The majority of our lab partners generate only PDFs that are sent through the mail to users. To describe the input that we are dealing with, let’s call them “Digital PDFs” produced using computers that contains text and can be searched for any text. As of now, we aren’t dealing with image converted PDFs (non-searchable PDF).After eyeballing a few reports from multiple labs, we made a few important observationsA lab report can be segmented into 4 parts depending on the content present

Title — Lab Details or logo
Header — Info about patient & sample
Body — Parameters with Values
Footer — Lab address & Other info
The Body is tabular with rows following the mentioned pattern across most of the labsParameter Name — Value — Units — Reference range
- Multiple pages are possible in a single PDF
…and many other minor features
Lab Labeller
Keeping the limitations & features discovered above, we set about developing a Rule-Based system that takes a PDF file & outputs standard diagnostic parameters names with values, units & reference range if mentioned.
We use Tabula to obtain text from PDFs
For digital PDFs, the text is already present within the PDF file which can be extracted using a python library, Tabula. Below is a sample of how Tabula extracts text from a PDF file
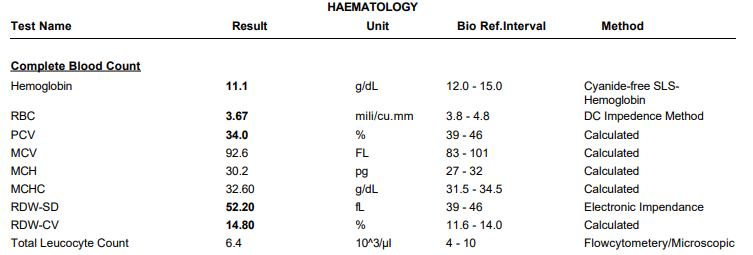
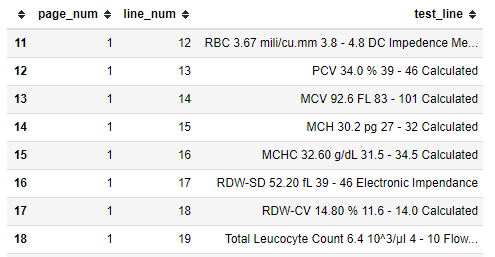
Next, we built a library of RegEx patterns to catch & standardize the Diagnostics Parameters found in Lab Reports
Some RegEx patterns were constructed after manually parsing over 100+ PDF reports. These Regex patterns help in extracting all existing ‘Raw Parameter Name — Value — Unit — Reference range’ sequences from the text returned from Tabula extraction.
Convert Parameter Name to Standard name
The last & most important step of this pipeline is to standardize the raw parameter name to a standard name. For this, we developed a set of ~500 RegEx patterns mapping a raw parameter name(extracted in the previous step) to a standard name. This has been done in 2 phases:
- If an exact match is found in the 500+ RegEx patterns, the mapped standard name is taken
- If not, the fuzzy match is used to find a standard name. Fuzz score between each possible standard parameter name & raw parameter is calculated & the best match is considered
A sample output from Lab Labeller is attached below
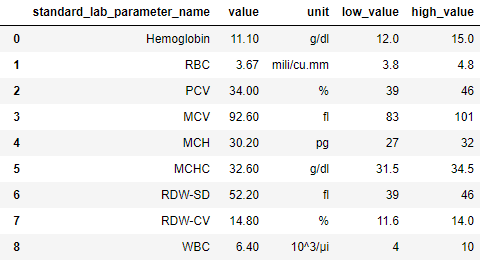
Note: Total Leucocyte Count’s standardized name is WBC.
Results & Performance
Why is setting performance benchmarks difficult? Because it is strictly based on some predefined rules or done over a Golden Dataset which would require considerable manual effort.However, performance should be continuously measured in terms of accuracy of extraction from the PDF. We should be able to answer affirmatively the following questions
- Is there zero difference between the (expected) number of parameters in the PDF and that found after digitization?
- Is there zero difference between the (expected) number of abnormal parameters highlighted in the PDF and that found outside normal after digitisation?
- Is there zero difference between the (expected) units of the parameters in the PDF and those for the ones found after digitisation?
- Is there zero difference between the (expected) values of the parameters in the PDF and those for the ones found after digitisation?
- Is there zero difference between the (expected) reference ranges of the parameters in the PDF and those for the ones found after digitization?
After a few rounds of brainstorming, the team came up with the concept of ‘validation rules’. A ‘validation rule’ can be defined as a rule on a field/value which verifies that data entered by a user meets certain criteria. These rules can help us in estimating the quality of results in absence of a Golden dataset. We have defined 2 such rules as of now
Component Validation: Given a test name, a flag is given to the parameters captured if it was expected in it using a CSV with test_name: frequent parameters to expect. So, If we find RBC in the ‘Fasting Blood Glucose ‘ test, most probably it is a False positive due to wrong standardization & hence can be rejected.
Value Validation: For a given Parameter-Value pair, if Value appears ambiguous (either too high or too low; done using z-score), the parameter may be wrong. So, If we get Average Blood Glucose = 100000 mg/dl, it is most probably wrong.
On estimating ‘Lab Labeller’ on these grounds, the performance looked good being accurate for most of the extractions & hence deployed for now.
Future Plans
We have three major directions to follow from here
- Improving Lab Labeller’s performance & train a Sequence labeller (as BiLSTM used for NER) using this digitized data
- Digitize Lab Report images (Users capturing hard copies using the camera & uploading them)
- Use this digitized data & build interesting applications over this to make lab reports easy to understand & quick to search out historic values.
So, that’s all for today. For any updates on what’s new happening in Lab Reports digitization, do visit the ‘Health Records’ section on the 1mg app and follow up this space.
Lab Reports Digitization was originally published in Tata 1mg Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.
- Log in to post comments
- 30 views