
Scalable task scheduling — Server-Less
Co-Authors: Pankaj Pandey, Prashant Mishra, Aman Garg
Introduction

At Tata 1mg, our daily operations encompass a wide array of background tasks, ranging from long-running processes, to extensive and time-consuming processes that don’t necessitate immediate execution before responding to REST API requests, to routine CRON-based tasks. In our quest for a robust and scalable solution, we sought a fault-tolerant task scheduler capable of seamlessly adapting to increased workloads. Specifically, our goal was to implement a task scheduler that could efficiently handle tasks in the queue without succumbing to back pressure, ensuring the timely processing of our operations.
Problem Statement
- Scalability and High Capacity: Our task scheduler will possess the capability to efficiently manage and process millions of tasks. This scalability ensures that as your workload grows, the system can seamlessly adapt to the increased demand, ensuring uninterrupted task scheduling.
- Fault Tolerance and Resilience: We prioritise building a fault-tolerant task scheduler that can handle unexpected failures gracefully. In cases of downstream target unavailability, our scheduler will employ smart retry mechanisms to ensure that tasks are eventually executed once the resources become accessible again. This ensures the reliability and resilience of your task scheduling system.
- Parallel Processing and Asynchronicity: To prevent any delays in task scheduling caused by a few long-running tasks, our system will be inherently asynchronous. It will be designed to process multiple tasks in parallel, allowing the scheduler to continue distributing other tasks without waiting for the completion of the time-consuming ones. This optimisation ensures efficient task management across your workload.
- Ease of Management and Low Maintenance Cost: We understand the importance of a system that is easy to manage and cost-effective to maintain. Our task scheduler will come equipped with user-friendly administrative tools and interfaces that enable seamless management. Additionally, we will design the system with built-in monitoring and diagnostic capabilities, reducing the need for extensive maintenance efforts.
In summary, our task scheduling solution will not only handle high volumes of tasks with fault tolerance and parallel processing but also provide a user-friendly management interface to ensure low maintenance costs and ease of operation. This comprehensive approach will empower your organization to efficiently manage and scale your task scheduling needs while minimizing operational overhead.
Solutions Considered:
After a thorough evaluation of multiple solutions, including Celery, Arq, Amazon Eventbridge Scheduler, Faktory, Aiotasks, and Huey, we ultimately narrowed down our choices to two final contenders: Celery and Amazon Eventbridge Scheduler. Let’s delve into the reasons why we ultimately chose to implement Amazon Eventbridge Scheduler for our specific use case.
Celery:
Celery is built around the concept of task queues as a core mechanism for distributing work in a distributed manner. Here’s a brief explanation of how task queues work in Celery:
- Task Definition: In Celery, a task is a unit of work that represents a specific job or computation that needs to be executed asynchronously. These tasks are typically defined as Python functions or methods.
- Task Producer: A task producer is responsible for creating and enqueueing tasks into the Celery task queue. This can be your application code, which generates tasks and sends them to the queue for processing.
- Task Queue: The task queue acts as an intermediary storage for tasks. It holds tasks until they are picked up for execution by Celery workers. The queue ensures that tasks are processed in the order they were received.
- Celery Workers: Dedicated Celery workers constantly monitor the task queue for new tasks. When a worker is available, it retrieves a task from the queue and executes it. Workers can be distributed across multiple machines, enabling parallel processing of tasks.
- Result Backend: Celery provides an optional result backend where task results can be stored. This is particularly useful for tasks that produce results that you need to retrieve later.
Supports multiple brokers like RabbitMQ, Redis, Amazon SQS. It Supports result stores like AMQP, Redis, Memcached, SQLAlchemy, Django ORM etc..
Amazon EventBridge Scheduler:
Amazon EventBridge Scheduler is a server-less scheduling solution managed by Amazon Web Services (AWS) that simplifies the orchestration of tasks and events. With EventBridge Scheduler, you can efficiently manage tasks from a centralised service, offering the flexibility to schedule a vast number of tasks that can trigger over 270 AWS services, providing exceptional versatility for your automation needs.One of its standout features is its built-in retry capabilities, which intelligently handle task execution based on the availability of downstream target services. This ensures the reliable execution of tasks, even in the face of intermittent issues with target services.EventBridge Scheduler is not only powerful but also cost-effective, with a low maintenance cost structure. AWS offers a generous starting point, providing 14 million free invocations per month. Beyond this free tier, the pricing is straightforward at just $1.00 per million scheduled invocations per month, making it an economically attractive choice for businesses of all sizes.For detailed pricing information, you can refer to the EventBridge PricingEventBridge Scheduler supports three types of schedules, making it adaptable to a wide range of use cases:
- One-time invocation based schedules: Ideal for scheduling events that need to occur just once.
- Rate-based schedules: Perfect for tasks that need to be executed at fixed intervals, such as every 5 minutes.
- CRON-based schedules: Provides advanced scheduling options using CRON expressions, allowing you to precisely define when events should take place.
A significant advantage of EventBridge Scheduler being serverless is that it eliminates the need for infrastructure provisioning and management. This means you can focus on scheduling and managing tasks without the overhead of infrastructure setup, enhancing your agility and simplifying your workflow automation.In summary, Amazon EventBridge Scheduler is a powerful, cost-effective, and versatile solution that streamlines task management and event scheduling, empowering businesses to automate their processes effortlessly and efficiently.Find detailed information of about EventBridge Scheduler here
The decision not to proceed with Celery and instead opt for Amazon EventBridge Scheduler is based on several key considerations:
- Infrastructure Overhead: Celery typically requires the setup and management of message brokers like RabbitMQ or Redis. This involves provisioning and maintaining the infrastructure, which can add complexity and operational overhead to your architecture. In contrast, EventBridge Scheduler is a serverless solution, which means AWS manages the underlying infrastructure, reducing your administrative burden.
- Integration and language support: Celery is primarily designed for Python and has excellent support for Python applications. While there are extensions and third-party integrations for other languages, it’s not as language-agnostic as AWS EventBridge.
- Data Reliability: When using Redis as a message broker with Celery, there is a risk of data loss in case of unexpected events such as power outages. To address this, you would need to configure Redis in a persistent mode, which can be more complex to set up and maintain. EventBridge Scheduler abstracts away these concerns and provides reliability features.
- Retry Handling: EventBridge Scheduler, as mentioned earlier, offers built-in retry capabilities based on the availability of downstream targets. This ensures that tasks are retried if the target services become temporarily unavailable. Celery may not provide the same level of automatic retry handling, requiring additional customization and complexity to implement retries when the broker is down.
- Asyncio Support: Celery’s support for asyncio is not as seamless or robust as desired. Depending on your use case, this limitation could impact the performance and scalability of your application. EventBridge Scheduler is integrated with AWS services and designed for serverless event-driven architectures, which can provide more streamlined async support.
In summary, the decision to use Amazon EventBridge Scheduler over Celery is motivated by a desire to simplify infrastructure management, enhance data reliability, and leverage built-in features for retry handling in a server-less and AWS-native environment. Each choice has its trade-offs, and the decision ultimately depends on the specific needs and constraints of your project.
How did we leverage EventBridge schedule at Tata 1mg
As mentioned earlier we need to run
- Recurring tasks, i.e rate based or CRON based invocations.
- Asynchronous tasks, i.e one-time invocations, just to run few tasks in background. For running jobs in back ground we have a separate background service, corresponding to each micro service. For example: reporting micro service will have a reporting background micro service.
Sample Requirement: Generate a daily report.
Task should get invoked at 1 AM every day which generates a report of events on previous day.
Design:serverless
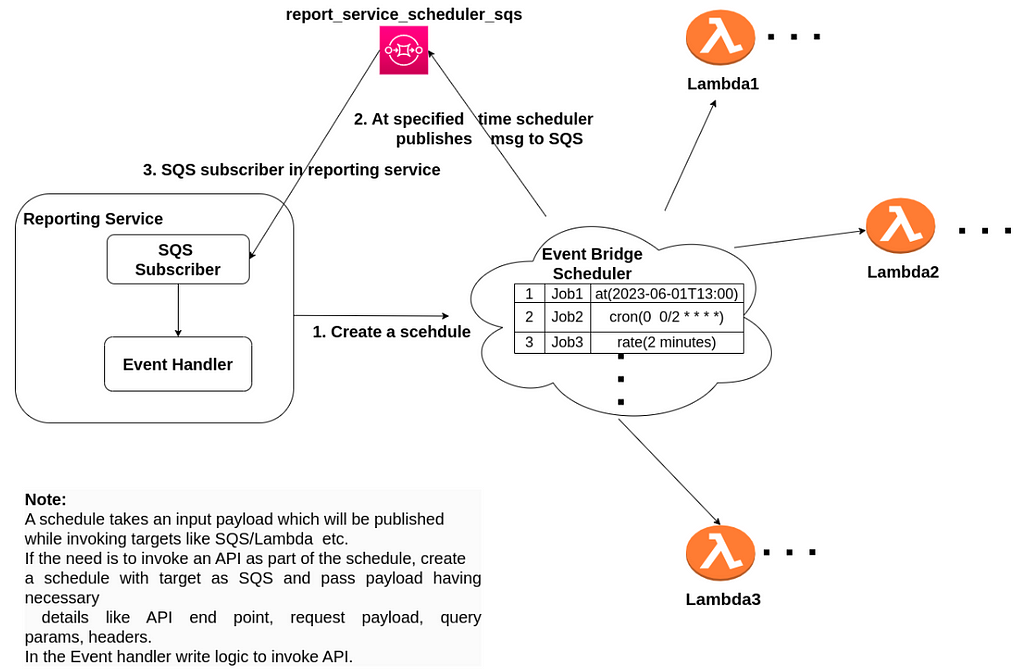
As per above diagramStep 1. Reporting service creates a eventbridge schedule using the amazon SDK, while creating the schedule the schedule_expression would be cron(0 1 * * *) , the target for the schedule will be reporting_service_scheduler_sqs, pass a msg (payload) with enough information on the JOB that needs to be done on receiving the message .Step 2. Eventbridge scheduler will put the message (the message passes during creation of schedule) to reporting_service_scheduler_sqsStep 3. The susbcriber in reporting service listening on reporting_service_scheduler_sqs receives the message and processes the message. In our case it will generate the daily report.
Note:
While EventBridge Scheduler does offer retries in case the target service encounters downtime, it’s essential to implement an additional fault-tolerant system to handle errors during the actual task processing. To address this need, we’ve incorporated Amazon SQS into our architecture. In this setup, messages in the SQS queue are not immediately deleted, allowing for retries through the use of visibility timeouts and in-flight attributes of SQS.To ensure efficient management of schedules, it is highly recommended to configure the ActionAfterCompletion attribute as "DELETE." By doing so, the scheduler will automatically delete the schedule upon successfully invoking the target. If this attribute is not set to "DELETE," EventBridge will not handle job deletion automatically. This applies not only to recurring schedules but also to one-time invocations. Without setting ActionAfterCompletion to "DELETE," schedules will persist even after execution, which can lead to unwanted clutter in your system. Therefore, it's crucial to adopt this configuration to maintain a clean and efficient scheduling environment.
Sample Python Code
This code supports creating three types of schedules:
- One time Schedule : at(2023–01–01T10:00:00)
- Rate based Schedule: rate(1 minutes)
- Cron based Schedule: cron(fields), A cron expression consists of six fields separated by white spaces: (minutes hours day_of_month month day_of_week year)
Supports two targets:
- SQS : This can also be used to invoke an API as part of the schedule.
- Lambda:
As we are discussing only about EventBridge Scheduler, I am attaching the code for creation of schedule groups and schedules, but not the code for subcribing to SQS. Schedule groups are just for grouping of schedules. Amazon provides a “default” group which can be used to create you schedules but it is recommended to use grouping for better maintenance.In the code snippet replace all place holders like <your-access-key> with relevant values.config = {"EVENT_SCHEDULER": { "EVENT_SCHEDULER_REGION": "ap-south-1", "AWS_ACCESS_KEY_ID":"<your-access-key>", "AWS_SECRET_ACCESS_KEY":"<your-secret-access-key>" } }schedule_client = SchedulerWrapper(config)//creating a group which will be used for our schedulesschedule_client.create_schedule_group("test-grp")// creating a schedule that puts a msg to SQS every 1 minute// if we want to create a schedule as per our reporting service requirement then// pass schedule_expression='cron(0 1 * * *)'schedule_client.create_sqs_event_schedule(schedule_name="my-sqs-schedule", schedule_expression='rate(1 minutes)', queue_name="<target SQS name>" msg='{sample payload}', schedule_description="description", group_name="test-grp")// creating a schedule that invokes the lambda, with given payload, every 1 minutepayload = {sample payload} schedule_client.create_lambda_event_schedule(schedule_name="my-lambda-schedule", schedule_expression='rate(1 minutes)', target_resource_name="<target lambda name>", msg=payload, schedule_description="description", group_name="test-grp")// below is the definition of SchedulerWrapper clazz, // used below versions of libraries// aiobotocore==2.5.0// aiohttp==3.7.3// botocore==1.29.76// python version used is 3.8import uuidimport jsonimport asyncioimport loggingfrom concurrent.futures import ThreadPoolExecutorfrom functools import partialfrom botocore.auth import SigV4Authfrom botocore.awsrequest import AWSRequestfrom botocore.credentials import Credentialsfrom botocore.session import get_sessionimport copyfrom aiohttp import ContentTypeErrorfrom aiohttp import ClientSession, TCPConnectorSESSION = NoneEVENT_SCHEDULER_CREATE_DEFINITION = { "Name":"", "Description":"", "GroupName":"", "ScheduleExpression":"", "FlexibleTimeWindow":{ "Mode": "OFF" }, "ScheduleExpressionTimezone":"Asia/Calcutta", "State":"ENABLED", "Target":{ "Arn": "", "Input": "", "RetryPolicy": { "MaximumEventAgeInSeconds": 1800, "MaximumRetryAttempts": 10 }, "RoleArn": "" } }class SchedulerWrapper(): def __init__(self, config: dict): self.config = config self.aws_domain = "amazonaws.com" self.event_scheduler_config = self.config.get("EVENT_SCHEDULER", {}) self.sqs_arn_dict = {} self.aws_region = self.event_scheduler_config.get("EVENT_SCHEDULER_REGION", "ap-south-1") self.aws_service = 'scheduler' self.path = "/schedules/{}" self.aws_access_key = self.event_scheduler_config.get("AWS_ACCESS_KEY_ID", None) self.aws_secret_key = self.event_scheduler_config.get("AWS_SECRET_ACCESS_KEY", None) self.aws_credentials = Credentials(self.aws_access_key, self.aws_secret_key) self.aws_sigv4 = SigV4Auth(self.aws_credentials, self.aws_service, self.aws_region) async def create_schedule_group(self, group_name="default"): schedule_group_definition = {"ClientToken": str(uuid.uuid1())} full_path = f"/schedule-groups/{group_name}" await self._call_aws_api(full_path, "POST", schedule_group_definition) async def _call_aws_api(self, full_path, method, schedule_definition): url = f"https://{self.aws_service}.{self.aws_region}.{self.aws_domain}{full_path}" headers = await self._get_aws_auth_headers(method, url, payload=schedule_definition) aws_response, status = None, None aiohttp_session = await BaseApiRequest.get_session() async with aiohttp_session.request(method, str(url), headers=headers, json=schedule_definition, timeout=60) as response: status = response.status if status == 200 or status == 409: # 409 is returned when the schedule/schedule group already exists try: aws_response = await response.json() except ContentTypeError as e: # in some api like delete schedule aws sends empty response with 200 status code pass else: aws_response = await response.text() _msg = "Error is AWS Schedule API with status code : {}, message: {}".format(status, aws_response) raise Exception(_msg) return status, aws_response async def _get_aws_auth_headers(self, method, full_path, payload=''): if not payload: data = None else: data = json.dumps(payload).encode('utf-8') request = AWSRequest(method=method, url=full_path, headers={ 'Host': f"{self.aws_service}.{self.aws_region}.{self.aws_domain}" }, data=data) with ThreadPoolExecutor(max_workers=1) as executor: loop = asyncio.get_running_loop() await loop.run_in_executor(executor, partial(self.aws_sigv4.add_auth, request)) return dict(request.headers) async def create_sqs_event_schedule( self, schedule_name, schedule_expression, queue_name, msg="", schedule_description="", group_name="default" ): """ Creates an Event Bridge Schedule whose target is an SQS :param schedule_name: Name of the schedule :param schedule_expression: Rate at which schedule should run. Example: 1. One time job: at(2023-06-02T13:30:00) 2. Job running at a regular interval: rate(1 minutes) 3. Job running at a regular interval using CRON: cron(fields) A cron expression consists of six fields separated by white spaces: (minutes hours day_of_month month day_of_week year) :param msg: Job Context, json that would be posted to SQS queue :param schedule_description: Description of this schedule job """ schedule_definition = SchedulerDefinition().event_scheduler_definition await self._create_schedule_definition( msg, schedule_definition, schedule_description, schedule_expression, schedule_name, queue_name, 'sqs', group_name ) await self._create_schedule(schedule_definition, schedule_name) async def _create_schedule_definition( self, msg, schedule_definition, schedule_description, schedule_expression, schedule_name, target_resource_name, target_type, group_name ): schedule_definition[Constant.SCHEDULER_NAME] = schedule_name schedule_definition[Constant.SCHEDULER_GROUP_NAME] = group_name schedule_definition["Description"] = schedule_description schedule_definition[Constant.SCHEDULER_EXPRESSION] = schedule_expression schedule_definition["ActionAfterCompletion"] = "DELETE" schedule_definition[Constant.SCHEDULER_TARGET]["Input"] = msg await self._add_target_definition(schedule_definition, target_resource_name, target_type) async def _add_target_definition(self, schedule_definition, target_resource_name, target_type): if target_type.strip() == 'sqs': arn = "<ARN of the target SQS>" // add code to fetch arn for the target_resource_name, in this case "ARN of the target SQS" _account_id = arn.split(':')[4] schedule_definition[Constant.SCHEDULER_TARGET][Constant.SCHEDULER_ARN] = arn schedule_definition[Constant.SCHEDULER_TARGET][ "RoleArn" ] = "<give the ARN that evenbridge scheduler should use, this role should have access to publish messages to concerned SQS>" elif target_type.strip() == 'lambda': arn = "<ARN of the target lambda>" // add code to fetch arn for the target_resource_name, in this case "ARN of the target lambda" _account_id = arn.split(':')[4] schedule_definition[Constant.SCHEDULER_TARGET][Constant.SCHEDULER_ARN] = arn schedule_definition[Constant.SCHEDULER_TARGET][ "RoleArn" ] = "<give the ARN that evenbridge scheduler should use, this role should have access to invoke lambda >" async def _create_schedule(self, schedule_definition, schedule_name): schedule_definition["ClientToken"] = str(uuid.uuid1()) full_path = self.path.format(schedule_name) await self._call_aws_api(full_path, "POST", schedule_definition) async def create_lambda_event_schedule( self, schedule_name, target_resource_name, schedule_expression, msg="", schedule_description="", group_name="default" ): """ Creates an Event Bridge Schedule :param schedule_name: Name of the schedule :param target_resource_name: Name of the target Lambda that will be triggered :param schedule_expression: Rate at which schedule should run. Example: 1. One time job: at(2023-06-02T13:30:00) 2. Job running at a regular interval: rate(1 minutes) 3. Job running at a regular interval using CRON: cron(fields) A cron expression consists of six fields separated by white spaces: (minutes hours day_of_month month day_of_week year) :param msg: Job Context, context that would be supplied to Lambda :param schedule_description: Description of this schedule job """ schedule_definition = SchedulerDefinition().event_scheduler_definition await self._create_schedule_definition( msg, schedule_definition, schedule_description, schedule_expression, schedule_name, target_resource_name, "lambda", ) await self._create_schedule(schedule_definition, schedule_name) class BaseApiRequest: @classmethod async def get_session(cls): global SESSION if SESSION is None: conn = TCPConnector(limit=0, limit_per_host=0) SESSION = ClientSession(connector=conn) return SESSION class SchedulerDefinition: def __init__(self): self.event_scheduler_definition = copy.deepcopy(EVENT_SCHEDULER_CREATE_DEFINITION)
Scalable task scheduling — Server-Less was originally published in Tata 1mg Technology on Medium, where people are continuing the conversation by highlighting and responding to this story.
- Log in to post comments
- 5 views