
One Reward to Rule Them All — Inside the Engine Powering Homepage Recommendation
In an e-pharmacy, the homepage (HP) is more than just a storefront — it’s a strategic touchpoint that can significantly influence a user’s journey. Customers often visit with specific intent, such as refilling prescriptions, browsing wellness products, or discovering health-related offers. A robust recommender system on the HP ensures that each user is presented with personalized, relevant content right from the first interaction, creating a seamless and engaging experience.Unpacking the Homepage: Your First Scroll, Our Biggest OpportunityBefore diving into the recommendation strategy, let’s break down what the homepage actually looks like.Picture it as a scrollable feed, stitched together from several widgets — each one designed to catch the user’s eye or fulfill a purpose. Some common widget types include:
- Carousels: Horizontally scrollable row displaying a curated set of paid promotions or offers, allowing users to swipe through multiple items within a single widget.
- Banner Promotions: Bold visuals featuring discounts, seasonal sales, or sponsored brands.
- Personalized Widgets : Widgets like “Continue browsing”, “Recommended for You” or “Previously Ordered Items“ based on the user’s history.
- Health Tips & Services: Informational sections about health conditions, diet & lifestyle, diagnostics, or preventive care.
- Exploration-Oriented: Like Product category-related widgets or L1L2
At any moment, only a handful of these widgets — typically 4 to 5 — are visible on the user’s screen, forming what we call the viewport.Here’s the catch: the order matters. The way these widgets are stacked influences whether a user scrolls deeper, clicks, buys, or leaves. Too salesy up front? Users might lose trust. Too boring? They won’t engage. That’s why ranking the right widget at the right position is critical — and why the homepage is prime real estate for smart recommendation systems.
The Multi-Goal Puzzle: What Makes Homepage Ranking Tricky
The homepage is made up of different widgets — think banners, carousels, product and category sections. The order in which these widgets appear isn’t random. The recommender system carefully ranks them, balancing several key objectives:
- Engagement:Simply put, we want to show widgets the user is likely to click on. If a user often browses vitamins, the system might rank that widget higher to grab attention.
- Monetization:Certain widgets are tied directly to revenue — whether through promotions, paid placements, or high-margin products. These need prominent spots, but without overwhelming the user.
- Conversion:The goal here is to help users quickly complete purchases. So, widgets showing refill reminders or recommended products based on user history may be ranked higher to make the process smooth.
- Exploration:It’s also valuable to introduce users to new products or categories. Widgets promoting lesser-known items or seasonal health tips might be ranked strategically to encourage discovery.
The Trade-off
The tricky part? These goals sometimes pull in different directions. The ideal recommender system ought to balance engagement, monetization, conversion, and exploration — to decide the final ranking. Done right, it creates a homepage that feels personalized and purposeful, benefiting both the user and the business.
Trials, Errors, and Insights: Solutions We Tested Along the Way
Every refined system is the result of a few imperfect beginnings. Our homepage recommender system didn’t start off as the sophisticated model it is today — it evolved through several iterations, each teaching us what not to do, and more importantly, what mattered.
1. The Manual Model: When Humans Did the Ranking
Before automation, personalization, or machine learning, our homepage widget ranking was handled the old-fashioned way — manually.Every day, a dedicated team would review basic engagement stats like clicks from the previous day and decide the ranking order of widgets for the next day. If Widget A had the highest clicks yesterday, it was bumped to the top today. Simple.Why We Started Here:
- Quick feedback loop: Easy to react to obvious trends — whatever users clicked most recently could get surfaced.
- Human control: Business teams could manually push priority widgets (like campaigns, offers) as needed.
Where It Fell Short:
- Lag in Decision-Making: Rankings changed only once per day, making them reactive rather than proactive.
- No Personalization: Every user saw the same homepage, regardless of their browsing or purchase history.
- Short-Term Bias: Over-reliance on previous day’s clicks ignored broader patterns like seasonality, user preferences, or long-term revenue impacts.
- Operational Overhead: Constant manual intervention made the process time-consuming and unscalable.
What We Learned:This model highlighted the limits of human-driven decisions in a fast-paced e-commerce environment. While it worked for short bursts, it couldn’t scale or adapt further. It was clear we needed to move towards automation and data-driven ranking.At this stage, our Data Science team stepped in to formalize the exploration-exploitation trade-off using a Reinforcement Learning (RL) mindset. Recognizing that static rules couldn’t balance short-term clicks with long-term gains, we conceptualized the homepage ranking problem as a sequential decision-making task — where each widget placement impacts future user behavior and rewards.
2. The Slate Multi-Armed Bandit Model: Learning to Fly
After realizing that manual rankings and static rules weren’t scalable or adaptable, we shifted gears towards a more dynamic, learning-based approach: the Slate Multi-Armed Bandit (MAB) model.At its core, our homepage ranking challenge is a classic decision-making problem under uncertainty — which is exactly where Reinforcement Learning (RL) shines.
Why RL Fits This Problem
Reinforcement Learning (RL) is all about learning to take the best possible actions in an environment to maximize a reward over time. In our case:
- Actions = Selecting a widget for each homepage slot
- Reward = User clicks (CTR)
- Environment = The ever-changing preferences of users interacting with the homepage
But here’s the tricky part: What worked well yesterday may not work today. New widgets are introduced, user interests shift, and business goals change. So we need a system that continuously learns and adapts — not a static rulebook. This is why RL principles are naturally suited for this ranking task.
The Exploration-Exploitation Dilemma
At the heart of RL (and our problem) lies the classic exploration vs. exploitation trade-off:
- Exploitation: Keep showing the widgets that have performed well in the past (maximize immediate clicks).
- Exploration: Try new or lesser-shown widgets to discover hidden gems (ensure long-term learning).
If we only exploit, we risk getting stuck showing the same widgets repeatedly, possibly missing better options. If we over-explore, we hurt short-term performance.
Enter Multi-Armed Bandits (MAB)
Multi-Armed Bandits simplify RL by focusing on this trade-off in a single-step decision-making setup (no long-term sequences like in full RL).
Approaches to MAB: Why We Chose UCB
Several popular strategies exist for balancing exploration & exploitation:
- Epsilon-Greedy: Picks the best-known option most of the time, but occasionally (ε% of the time) explores randomly. Simple, but can waste exploration chances.
- Thompson Sampling: Uses probability distributions to sample the likely best option. Highly effective, but computationally heavier, especially with large widget pools and multiple slots.
- Upper Confidence Bound (UCB): Picks the widget with the highest upper bound on its expected reward — essentially favoring options with either high average clicks or those with less exposure (i.e., uncertainty).
For our problem, UCB struck the right balance:
- It naturally gives under-explored widgets a chance.
- It prioritizes high-CTR widgets without the need for manual randomness (unlike epsilon-greedy).
- It’s computationally efficient compared to more complex approaches like Thompson Sampling, especially important when scaling across all homepage slots.
Diving Deeper: How UCB Makes Smarter Choices
At the core of our Slate MAB model lies the Upper Confidence Bound (UCB) algorithm — a simple yet effective strategy that helps each slot decide which widget to show, purely based on two key factors:
- CTR (Click-Through Rate): How often users clicked on the widget when it was shown.
- Number of Tries: How many times the widget has been displayed so far.
How UCB Works
UCB assigns each widget a score using this formula:UCB Score = Average CTR + Exploration BonusThe exploration bonus is larger for widgets that haven’t been shown much, encouraging the model to give them more exposure. Over time, as the model gathers more data, it naturally balances:
- Exploitation: Favoring widgets with high CTR.
- Exploration: Giving under-tested widgets a chance, avoiding the risk of missing hidden performers.
The UCB reward looks like this :
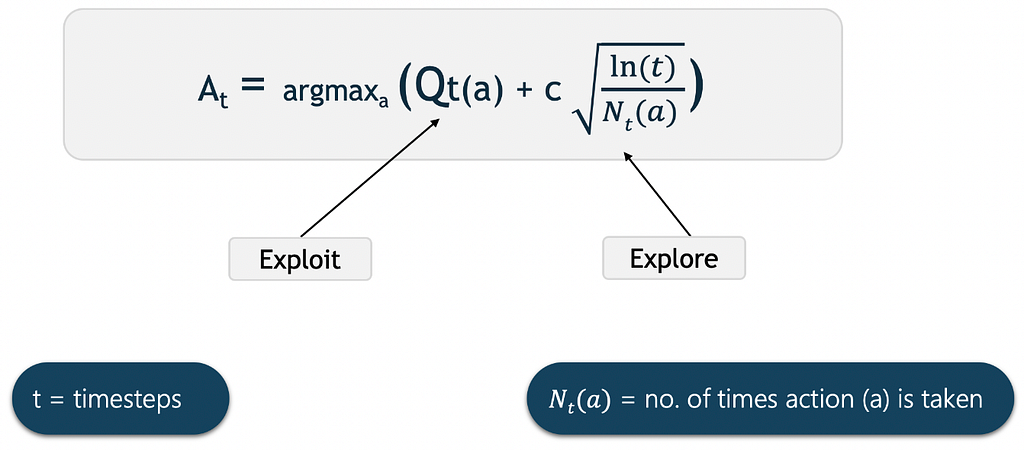 Reward Estimation in UCB
Reward Estimation in UCBQt(a) here represents the current estimate for action a at time t (This would be the average CTR for a widget at a slot until time t in our context) We select the action that has the highest estimated action-value plus the upper-confidence bound exploration term.
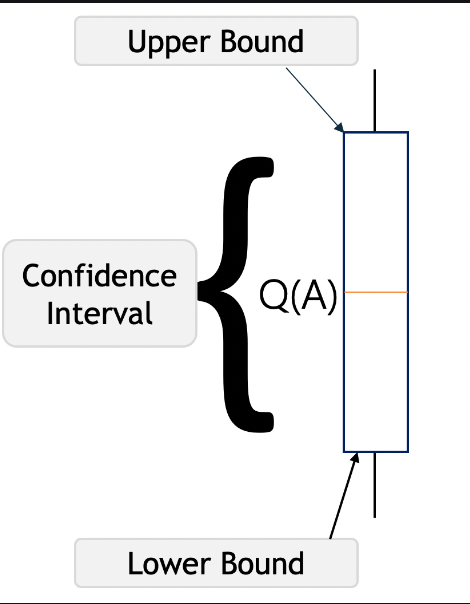
In UCB, Q(A) represents the estimated value of action A, surrounded by a confidence interval. The lower and upper bounds indicate how certain we are about the estimate — the narrower the interval, the more confident we are; the wider it is, the more uncertainty exists.UCB follows the principle of optimism in the face of uncertainty. When uncertain, it assumes the best-case scenario and picks the action with the highest upper bound. This way, either it selects a genuinely high-reward action, or it gathers more information about lesser-known actions, improving future decisions.

Let’s assume that after selecting the action A we end up in a state depicted in the picture below. This time UCB will select the action B since Q(B) has the highest upper-confidence bound because its action-value estimate is the highest, even though the confidence interval is small.

Initially, UCB explores more to systematically reduce uncertainty but its exploration reduces over time. Thus we can say that UCB obtains greater reward on average than other algorithms such as Epsilon-greedy, Optimistic Initial Values, etc. Also UCB implicitly takes care of the Exploration objective of our Homepage problem.UCB approach worked well because it was:
- Computationally light
- Slot-specific (each slot’s MAB works independently)
- Free from randomness (unlike epsilon-greedy)
How it was all put together — The Architecture:
Think of each position (or slot) on the homepage as a separate decision point — Slot 1, Slot 2, Slot 3, and so on. For every slot, we attached its own Multi-Armed Bandit (MAB) algorithm.
- Each widget (like “Top Offers,” “Reorder widget,” or “Carousel”) acted as an “arm” of the bandit.
- Each bandit decided which widget to show in that slot, learning from two key signals:
- CTR (Click-Through Rate): Whether users clicked on the widget when it was shown.
- Number of Attempts (Exploration): Ensuring each widget got enough chances before the system leaned too heavily on a few top performers.
This setup allowed the system to experiment — trying different widgets across slots, gathering data on user behavior, and gradually favoring the ones that attracted more clicks. Unlike the earlier models, rankings here evolved in real time, adjusting based on fresh user interactions.To use the MAB analogy“Imagine each slot on the homepage as a slot machine (the bandit). Each machine has multiple levers (widgets). The system keeps pulling different levers, learning over time which lever (widget) gives the highest reward (clicks) at each position.”
Curation: Stitching Together the Final Homepage Ranking
In our Slate MAB setup, each slot (position) on the homepage had its own dedicated MAB, independently selecting the widget it believed would perform best based on click data and exploration.However, after these individual decisions, we needed to curate the final homepage lineup to ensure a smooth and coherent user experience:
- Remove Duplicates: Multiple MABs could choose the same widget. We ensured each widget appeared only once on the homepage.
- Resolve Conflicts: If two slots selected the same widget, we prioritized the higher slot and allowed the lower one to choose its next-best option.
3. Blend Widget Types: To avoid stacking similar widget types together (like three promo banners in a row), we implemented a Blending Engine. This layer enforced diversity rules, adjusting the MABs’ output to improve user experience and prevent content fatigue.
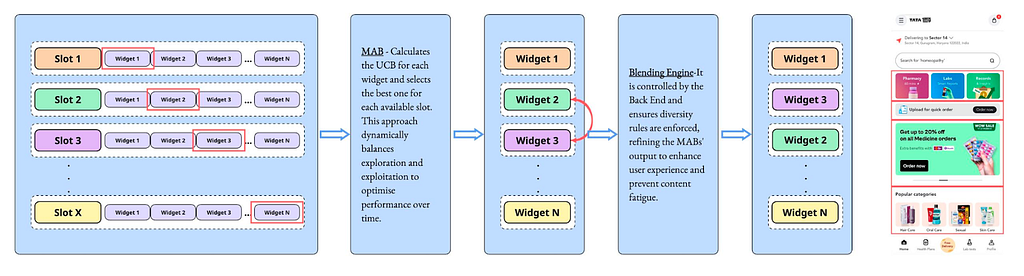 The Homepage Architecture — CTR based UCB approach
The Homepage Architecture — CTR based UCB approachThe Limits of Chasing Clicks: Where Model 2 Fell Short
While our Slate MAB model with UCB brought automation and adaptability, it had one core assumption baked in:Maximize engagement (CTR), and everything else — revenue, conversions, exploration — will take care of itself.Unfortunately, that assumption didn’t hold up well in the real world.
Here’s why:
- Engagement ≠ MonetizationJust because a widget gets clicks doesn’t mean it drives revenue. Some widgets, like promotional banners, might have low CTR but high business value — either due to sponsored placements or high-margin products.
- Engagement ≠ ConversionHigh CTR widgets might attract clicks but not necessarily lead to purchases. For example, users were frequently clicking on the “Popular category” widget but weren’t actually checking out products through it.
What We Learned
CTR alone was too narrow a reward signal. By focusing solely on short-term clicks, we risked missing larger business objectives like:
- Maximizing revenue and margins.
- Increasing conversions and order completions.
- Promoting underexposed monetized categories.
This realization set the stage for us to rethink the reward design — beyond clicks — to align the homepage ranking with all of our key goals.
3. The Multi-Objective MAB: Where Engagement Meets Business Goals
To truly optimize the homepage, we needed a reward function that reflected all key goals engagement, monetization, conversions while still being flexible, automated, and scalable.Our team proposed a reward function built on three key metrics:
- CTR (Click-Through Rate) → capturing engagement.
- GMV (Gross Merchandise Value) → reflecting conversion value.
- MR (Monetization Revenue) → capturing revenue from sponsored or monetized widgets.
 Ingredients of a good e-commerce reward
Ingredients of a good e-commerce rewardStep 1: EDA — Unpacking Widget Behavior Across Positions
We began with a thorough Exploratory Data Analysis (EDA), focusing specifically on how key metrics behaved across homepage slots:
- CTR (Click-Through Rate)
- GMV (Gross Merchandise Value)
- MR (Monetization Revenue)
- Margin
We plotted these metrics against the number of widget impressions at each position, looking for patterns like:
- How engagement varied by slot position for various widgets
- Which widgets consistently contributed to revenue or margins, regardless of CTR.
- Whether performance tapered off in lower positions.
This analysis revealed important insights: position heavily influenced engagement, but revenue contributions didn’t always correlate linearly with clicks — highlighting the need to think beyond CTR.
Step 2: Simulating Rankings — Experimenting with Multiple Signals
Once EDA shaped our initial understanding, we moved to virtual ranking simulations to test different reward configurations.Here’s where we expanded beyond the basic metrics:
- During simulations, we experimented with weighting additional signals like checkout rates, Add-to-Cart (ATC) events, and position-specific clicks.
- Each simulation involved adjusting weights across CTR, GMV, MR, margin, ATCs, and checkouts, generating hypothetical rankings.
- We evaluated each setup to see how well it balanced engagement, monetization, and conversion metrics under real-world constraints.
What Guided Us:
We didn’t guess the reward design. We built it step by step, grounding it in data, stress-testing it through simulations, and letting real business objectives shape its final form.
From Chaos to Clarity: How the Right Reward Solved Everything
- We continued using our existing Slate MAB architecture with minimal changes.
- Automated the system end-to-end, removing manual oversight.
- Balanced engagement, monetization, and conversion — all captured cleanly through CTR, MR, and margin metrics.
- Ensured scalability while aligning the model’s behavior with key business goals.
Performance Analysis: A/B and final release CTR metrics
In this experiment, we evaluate the impact of automation of the ranking of widgets on the Homepage as mentioned above. Specifically, we compared two cohorts: one where our reinforcement algorithm — the MAB dynamically optimises the ranking based on the requirements of engagement, conversion and monetisation, and another where the ranking was manually curated. This A/B test helps assess the effectiveness of automated decision-making versus human-driven strategies in our e-pharmacy setting.We initially began only on Android where we had divided the cohorts by randomly assigning users to one of 3 cohorts being:
- Test Cohort: In this group, users were presented with an automated ranking. It accounted for 10% of the total traffic.
- Control 1: This cohort featured a manually curated ranking and comprised 45% of the traffic.
- Control 2: Similar to Control 1, this cohort also used the same manual ranking and represented the remaining 45% of the traffic.
We included two Control cohorts using the same ranking to eliminate any bias stemming from user interactions with the Homepage. The metrics in both cohorts were remarkably similar.We let the experiment run for 14 days and observed the following results:

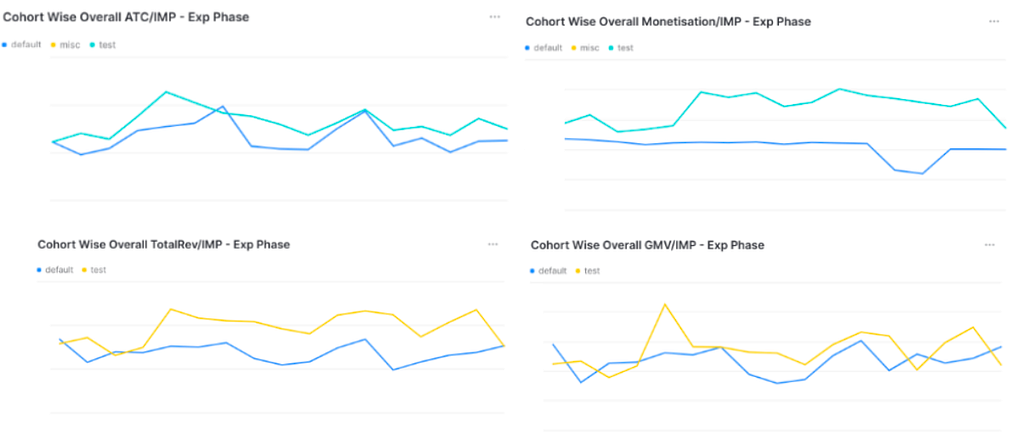
The overall CTR of the Homepage remained largely stable, while all downstream metrics saw a substantial surge. Following the outstanding success of the Automated Ranking, driven by the synergy of the MAB and Blending Engine, we expanded its deployment to 100% of Android users.We successfully replicated the experiment on iOS, maintaining the same setup. To highlight the impact of automation, I will showcase a comparative analysis of 14 days of data before and after the scale-up, demonstrating its effectiveness and measurable success. This analysis aims to illustrate the significant impact achieved through scaling up.
 iOS A/B results
iOS A/B resultsThe A/B experiment proved the exceptional effectiveness of the Automated Ranking of widgets on the Homepage, powered by the synergy of the MAB and Blending Engine. While the overall Homepage CTR remained stable in both Android and iOS, downstream metrics saw a significant uplift, validating the impact of automation. Encouraged by this success, we scaled the solution to 100% of Android as well as iOS, achieving impressive results. The comparative analysis before and after scale-up further reinforces the transformative power of automation in driving engagement and performance.
In Conclusion
Homepage recommendation often feels like a black box from the outside — but behind every smooth, intuitive experience lies a series of deliberate, technical decisions.In our journey, we started with manual curation, shifted to rule-based systems, and experimented with bandit-based models. Each step taught us what worked — and more importantly, what didn’t.What began as a straightforward engagement optimization problem soon evolved into a multi-objective balancing act: clicks alone couldn’t drive revenue; monetization widgets needed to be surfaced without compromising user experience; conversions couldn’t be sidelined for short-term gains.The key realization? Reward design is everything.By carefully crafting the right reward function — one that embedded engagement, revenue, and margin signals — we aligned the model’s behavior with broader business goals.
One Reward to Rule Them All — Inside the Engine Powering Homepage Recommendation was originally published in Tata 1mg Technology on Medium, where people are continuing the conversation by highlighting and responding to this story.
- Log in to post comments
- 2 views