
Multi-Armed Bandit — AB Experimentation 2.0

A/B testing or Split Testing is the process of comparing two or more variations of a page element, usually by testing users’ response to variant A vs variant B, and concluding which of the variants is more effective. Running an experiment is a multi-domain task involving Engineering, some Data Engineering, and mainly Analytics.Most of the successful experiments are where each of these entities are developed in a focused manner. Each individual does specialized tasks that require specialized solutions to deal with the volume, variety, and velocity of incoming data.
- An Engineer builds a function to randomly divide the audience into two or more parts and send them to the various experiment variants.
- Scaling is dependant on the underlying Control and Target variants and not on the division logic
- Collecting logs about the decision is done by sending key-value pairs in the API response which is captured by the Data Pipeline
- A Data Engineer works on collecting data about the user’s preferences. They build transformations and data ingestion pipelines to get impressions and rewards in the Data Warehouse
- Finally, an Analyst or Data Scientist builds cohorts, defines metrics, and OKRs to understand whether the solution worked as intended or not
These folks work and share subjective feedback with each other to solve the underlying problem by running an AB experiment.The term “Multi-Armed Bandits” starts featuring in conversations when there is a need to automatically scale AB experiments to the next level, hence the name for the document.
Scaling AB Experiments …
… could mean a lot of things. The journey of scaling starts from a simple AB experiment to Multivariate testing. From Multivariate testing it can progress to Multi- page funnel testing as shown below.
 Multi-page funnel testing (https://help.optimizely.com/)
Multi-page funnel testing (https://help.optimizely.com/)Automating AB Experiments …
… by automating decisions for adding new choices to AB experiments, automating decisions to split traffic, automating the retraining of a data science model, etc. Modularising these components and integrating them can bring speed and productivity that can take an idea from the drawing board to production in a matter of minutes.
Benefits of Scaling and Automating
- Accelerate Learnings — We can reduce experiment duration by showing more visitors the variations that have a better chance of reaching statistical significance. We can attempt to discover as many significant variations as possible, thus maximizing the number of learnings from experiments in a given timeframe and spending lesser time waiting for results
- Accelerate Impact — We can maximize the payoff of the experiment by showing more visitors the leading variation. We exploit as much value from the leading variation as possible during the experiment lifecycle, thereby avoiding the opportunity cost of showing sub-optimal experiences
Multi-Armed Bandit — What’s this?
The name comes from imagining a gambler (Bandit) at a row of slot machines (Multiple Arms), who has to decide which machines to play, how many times to play each machine, and whether to continue with the current machine or try a different machine.
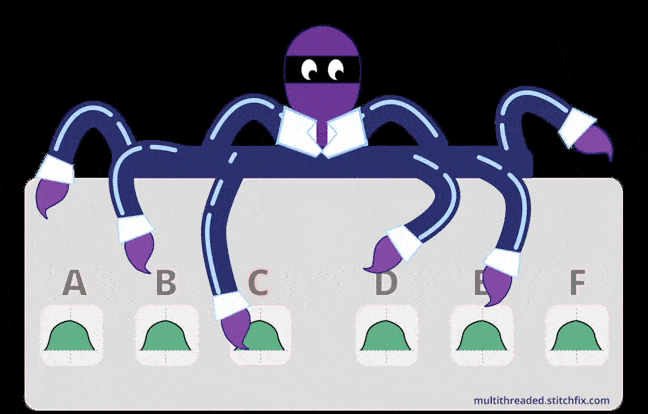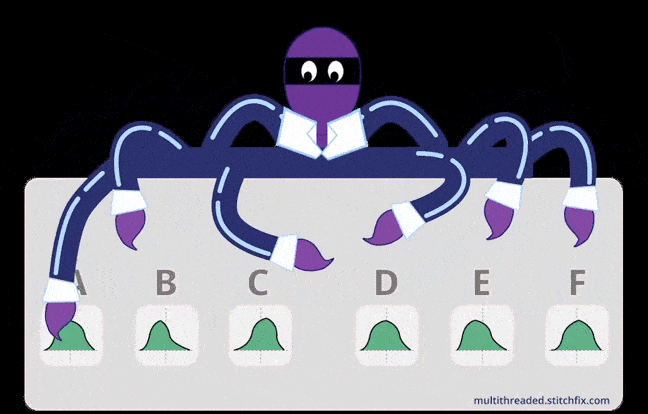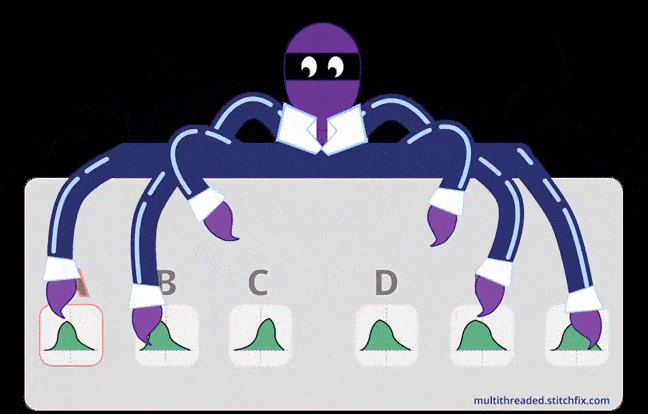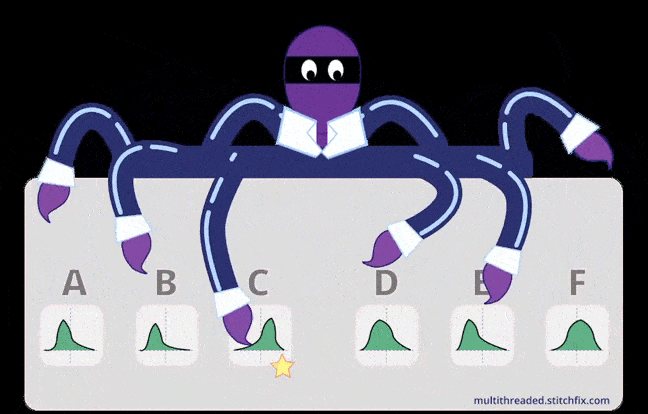 An illustration to depict basic intuition for MAB (multithreaded.stitchfix.com)
An illustration to depict basic intuition for MAB (multithreaded.stitchfix.com)In the multi-armed bandit problem, each machine provides a random reward from a probability distribution specific to that machine. The objective of the gambler is to maximize the sum of rewards earned through a sequence of lever pulls.
Exploration-Exploitation Tradeoff
The crucial tradeoff at each trial is between “exploitation” of the machine that has the highest expected payoff and “exploration” to get more information about the expected payoffs of the other machines.
Multi-Armed Bandit is a problem framework that can be applied to many practical scenarios like Scaling and Automating AB Experiments
 Exploration and Exploitation tradeoff
Exploration and Exploitation tradeoffThe multi-armed bandit problem models an agent that simultaneously attempts to acquire new knowledge (called “exploration”) and optimize their decisions based on existing knowledge (called “exploitation”)
Expectations from Multi-Armed Bandit
Before diving deeper into how a MAB framework solves the above-mentioned tradeoff and therefore helps us scale a simple AB framework, let’s take a moment to understand the applications where such a design would allow efficiency and remove bottlenecks.
MAB helps us automate the process of going from Zero to 100km/hr or from a cold-start situation to a well informed one.
Following are some situations where a MAB framework can improve the speed and effectiveness of the AB Experimentation framework. Situations where there is a …
- Need to allocate more traffic to Variants that perform better or have better Rewards
- Need to scale an AB Experiment from having just 2–3 Variants to 100s or 1000s of Variants
- Need to dynamically add New Variants without worrying about the traffic distribution
- Need to use multiple Rewards like Clicks, Add to Carts or Orders or a complex metric using all three
- Need to use Context to ensure multiple best arms instead of a single one
- Ability to use historical information about the user
- Ability to use information about the present situation like Geography, Cart Attributes etc
- Ability to use information about the actions being shown to the user
Solving the Multi-Armed Bandit Problem — The Challenges
There are many algorithms that can be used to solve the MAB problem ranging from LinUCB to Deep Q-Learning and Soft Actor-Critic Methods. However, before attempting to solve the MAB problem, there are many challenges right from initiating the MAB to deploying a robust scalable multi-armed bandit solution.
Challenges
Data Collection for Impressions and Rewards
There are multiple sources that record impressions and rewards. These need to be joined and aggregated to get ROI for each Arm or Variant
Exploration New Variants
Every time a New Variant is introduced, we allocate precious ‘real-estate’ on the platform to them which could increase losses. Not showing New Variants can cause lost opportunity cost.
Handling 1000s of Variants in MAB
Testing 100s and 100s of Variants for a MAB experiment can open doors for building recommendation lists like Cart Fillers and Trending Products list.
Incorporating Context
Context can be about historical information about the User, information about the present situation like Platform, Geography, Cart Attributes, etc, information about Arms or Variants being shown to the user
Configuring any AB Experiment should be simple
We define three types of MAB configurations currently,
- Simple MAB — Output is a Single Best Arm
- Slate MAB — Output is a Slate of Best Arms one for each Position
- Contextual MAB — Output is a Slate of Best Arms one for each Position but input can have a Context
A simple MAB experiment can be configured by the following steps:
- Define Arms — Create an Experiment and Specify the Arms for the Experiment
- Define Arm Rewards — Define the Initial Masked ROIs for each Arm
- Serve Experiment — Experiment gets served using the Initial Masked ROIs. Traffic is distributed and the Arms with higher ROI get more traffic.
- The Output is a Single Best Arm based on a simple ROI function and sorting logic
- Update Arm Rewards — Arm ROIs can be updated to change the distribution of traffic
A Slate MAB experiment is similar with a difference, where the Output is a Slate of Best Arms one for each Position. Underneath a Slate, we run a Simple MAB for each position and fill them in ascending orderIn Contextual Slate MAB, additional configuration of context and model to use is added. The Output should be exactly the same, a Slate of Best Arms one for each Position. Also, while requesting for a Slate, Context variables could be provided like products in cart.In our next article in the Multi Arm Bandit series, we will be discussing our implementation of the slate MAB at 1mg, specifically to optimize the listing of our cart filler products followed by a review of an implementation of contextual MAB algorithm.Stay tuned..
Multi-Armed Bandit — AB Experimentation 2.0 was originally published in Tata 1mg Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.
- Log in to post comments
- 1 view