
Building a Clearer Picture: Rethinking Log Messages and Log Pipeline for Superior Observability at 1mg
Co-Authors:
- Pankaj Pandey (Senior Technical Architect / Director of Engineering, SCM Tech @ Tata 1mg)
- Vimal Sharma (Technical Architect @ Tata 1mg)
- Aman Garg (Associate Technical Architect @ Tata 1mg)
Introduction
In the fast-paced world of software engineering and operations, maintaining a robust observability strategy is crucial for ensuring the performance and reliability of systems. In this article, we’ll dive deep into how 1mg undertook a transformative journey by reimagining their approach to log messages and log pipelines, resulting in better observability practices.
Problem Statement
Log messages are really important for understanding how software works, spanning from backend services to frontend services to networking tools like Nginx. However, the growing array of technology stacks, each with its distinct log message format, presents a challenge in maintaining their comprehensibility. The main challenge is making sure that log messages stay important, no matter what kind of technology in our tech stack generates them.The next problem is to design a log pipeline system that is efficient, scalable, highly available, and does not negatively impact the application layer.Read on to find out how we tackle these challenges at Tata 1mg.
Common log message format
We strongly believe that the log message format used across services (irrespective of the programming language and framework) must be the same. The number of parameters that are logged as part of a log message must be fixed and pre-defined.Adopting a standardized log message format enhances our logging and monitoring setup, leading to a robust pipeline. This eliminates the need for an intermediary parsing layer, reducing ongoing maintenance resources, and offers flexibility to smoothly integrate new languages and frameworks without jeopardizing our logging pipeline’s integrity.
What should be logged?
- Access log — the standard access log of a service. It captures the requests being serviced by a service and standard request analytics parameters.
- Background tasks — the information about the background tasks running in a service.
- External calls — log about the external calls being made by the service. This includes inter-service calls (HTTP/TCP), HTTP calls to an external system or calls to DB, Cache, or other stacks.
- Custom logs — These are log messages added to the application layer. These are added by engineers while working with a piece of code in order to log some information that they wish to look at at a later point in time.
A unique identifier for each request
We have implemented a mechanism to allocate a distinct request ID to every incoming request upon its entry into our infrastructure. Comprehensive measures have been taken across various layers to ensure the seamless propagation of this request ID to all services involved in catering to the request. This robust practice empowers us with the ability to trace the journey of a request across services, thereby facilitating comprehensive insights into the sequence of events and their respective occurrences.
The log message format
Each and every log message in our system is now a JSON document. A few fields in the document are mandatory and are part of each and every log message while some are contextual and will be present in a particular type of log message. The inclusion of ‘request_id’ in all log messages and provision of some of the unconventional keys (keys not common in standard log messages, like keys to log external calls as described below) has enhanced our ability to gain comprehensive insights and conduct in-depth system analysis.The JSON document looks something like this -{ //generic - mandatory in all the log messages "version": "v2", # v2 denotes new format "request_id": "5dd5bafc-d8a8-4e1d-b12c-96902d203ec5", "timestamp": "2022-09-23T10:41:48.258Z", # format - %Y-%m-%dT%H:%M:%S "logtype": "access/custom/background/external", "loglevel": "DEBUG/INFO/ERROR/EXCEPTION", //service deployment related - mandatory in all the log messages "service_name": "", "branchname": "", "host": "10.0.46.179:39628", //message - all "message": "Max 100KB <For customer logs, application logs go in this. For exceptions (handled/unhandled) the message is the raised error message>", // Request info - for logtype=access logs only "status_code": 200, "http_method": "GET", "uri": "/v6/info", "user_agent": "Python/3.4 aiohttp/0.20.2", "bytes_sent": 1198, "referer": "upstream_service", "source_ip": "<Public IP of the requester>", // Request performance - for logtype=access logs only "response_time": "<int>response time at app level in ms", //Exception details and tracebacks - for loglevel=exception logs only "exception_type": "HTTPRequestException", "traceback": "<traceback>", //External calls - for logtype=external "external_protocol": "<http/https/tcp>" "external_host": "<host>" "external_endpoint": "<URI for http, method name for tcp>", "external_method": "<for external_protocol=http/https only>", "external_status": "<http status>", "external_time_taken": "<time taknen in milli seconds>" ,}The relevant information, held in the responsible service, was included in the log message through framework adjustments and library patching across our services and Nginx environment.An example of how we patched Python’s logging library to make sure log messages adhere to the above format in all our Python services written on the Sanic framework —
Disclaimer: You might notice that the code below mentions functions or variables not present in this example. This was done on purpose to keep the code short and focus on explaining the concept.
from pythonjsonlogger import jsonloggerclass CustomTimeLoggingFormatter(jsonlogger.JsonFormatter): def __init__(self, *args, **kwargs): super(CustomTimeLoggingFormatter, self).__init__(*args, **kwargs) self.datefmt = "%Y-%m-%dT%H:%M:%S" self.rename_fields = { "levelname": "loglevel", "status": "status_code", "asctime": "timestamp" } def format(self, record): """Formats a log record and serializes to json""" message_dict = {} if isinstance(record.msg, dict): record.message = json.dumps(record.msg) else: record.message = record.getMessage() # record.message can't be more than 100KB in size # There are approximately 2000 chars in 100KB if len(record.message) > 2000: record.message = record.message[:2000] + '.....' # only format time if needed if "asctime" in self._required_fields: record.asctime = self.formatTime(record, self.datefmt) # Display formatted exception, but allow overriding it in the # user-supplied dict. if record.exc_info and not message_dict.get("exc_info"): message_dict["exception_type"] = record.exc_info[0].__name__ message_dict["exc_info"] = self.formatException(record.exc_info) if not message_dict.get("exc_info") and record.exc_text: message_dict["exc_info"] = record.exc_text # Display formatted record of stack frames # default format is a string returned from :func:`traceback.print_stack` try: if record.stack_info and not message_dict.get("stack_info"): message_dict["stack_info"] = self.formatStack(record.stack_info) except AttributeError: # Python2.7 doesn't have stack_info. pass try: log_record = OrderedDict() except NameError: log_record = {} self.add_fields(log_record, record, message_dict) log_record = self.process_log_record(log_record) if log_record.get("request"): request = log_record.get("request") log_record["method"] = request.split(" ")[0] log_record["url"] = urlparse(request.split(" ")[1]).path log_record["params"] = urlparse(request.split(" ")[1]).query log_record['traceback'] = log_record.pop('exc_info', None) log_record.pop("name", "") return self.serialize_log_record(log_record)def patch_logging(config): """ We are patching the standard logging to make sure - 1) Each log record is a json log record 2) Log record is consist of pre-defined set of keys only 2) Each log record has all the pre-defined mandatory keys in it 3) Put a limit on the log message length/size """ # Don't patch if the app is running in DEBUG mode if config.get('DEBUG'): return log_message_format = "%(asctime)s - %(name)s - %(levelname)s - %(message)s" ################################ # Patch LogRecordFactor of the logging module to include mandatory log parameters ################################ old_factory = logging.getLogRecordFactory() def record_factory(*args, **kwargs): record = old_factory(*args, **kwargs) try: record.request_id = context.get('X-REQUEST-ID') except Exception as e: record.request_id = '-' # define logtype logger_name = record.name if logger_name == 'sanic.access': record.logtype = LogType.ACCESS_LOG.value elif logger_name == 'aiohttp.external': record.logtype = LogType.EXTERNAL_CALL_LOG.value elif record.request_id is None or record.request_id == '-': record.logtype = LogType.BACKGROUND_CUSTOM_LOG.value else: record.logtype = LogType.CUSTOM_LOG.value record.service_name = ServiceAttribute.name record.branchname = ServiceAttribute.branch_name record.current_tag = ServiceAttribute.current_tag record.host = '{}:{}'.format(ServiceAttribute.host, ServiceAttribute.port) # TODO put a check on length of record.message. If the length/size is more than the specified limit, truncate the message # log record version record.version = 'v2' return record logging.setLogRecordFactory(record_factory) ################################ # Patch Sanic access log writer to include customer access log parameters ################################ def log_response_custom(self) -> None: """ Helper method provided to enable the logging of responses in case if the :attr:`HttpProtocol.access_log` is enabled. """ req, res = self.request, self.response extra = { "status_code": getattr(res, "status", 0), "bytes_sent": getattr( self, "response_bytes_left", getattr(self, "response_size", -1) ), "uri": "", "user_agent": "", "http_method": "", "response_time": "", "source_ip": "-", "referer": "-" } if req is not None: extra['uri'] = req.path extra['http_method'] = req.method extra['user_agent'] = context.get("X-USER-AGENT") extra['response_time'] = context.get("response_time") logging.getLogger('sanic.access').info("", extra=extra) Http.log_response = log_response_custom ################################ # Patch lastResort handler of the logging module - this is used a default handler for loggers with no handlers ################################ fmt = CustomTimeLoggingFormatter(log_message_format) logging.lastResort.setFormatter(fmt) ################################ # Make sure whenever a new handler is created CustomTimeLoggingFormatter is attached to it as formatter. # Instead of patching the logging.Handler.__init__ we have patched the the logging._addHandlerRef method because # logging._addHandlerRef is always called when a new handler is instantiated and it's relatively each to # patch this method ################################ def _add_handler_ref_patched(handler): """ Add a handler to the internal cleanup list using a weak reference. """ from logging import _acquireLock, weakref, _removeHandlerRef, _handlerList, _releaseLock _acquireLock() try: fmt = CustomTimeLoggingFormatter(log_message_format) handler.setFormatter(fmt) _handlerList.append(weakref.ref(handler, _removeHandlerRef)) finally: _releaseLock() logging._addHandlerRef = _add_handler_ref_patched ################################ # All the handlers must have the CustomTimeLoggingFormatter as formatter. # So patch the logging.Handler.setFormatter method to ignore the setFormat operation ################################ def _set_formatter_patched(self, fmt): """ Set the formatter for this handler. """ if not isinstance(fmt, CustomTimeLoggingFormatter): return self.formatter = fmt logging.Handler.setFormatter = _set_formatter_patched ################################ # Update formatter in existing handlers ################################ for weak_ref_handler in logging._handlerList: handler= weak_ref_handler() fmt = CustomTimeLoggingFormatter(log_message_format) handler.setFormatter(fmt)The ‘patch_logging’ method is invoked as the first step in the service start process. Patching makes sure that the log messages emitted by the service adhere to the new format.
Revamped Log Pipeline
After careful consideration of the various tools and technologies available to build the log pipeline, spanning from the renowned open-source ELK stack to several modern-day paid solutions, we settled with a tailored log pipeline built atop open-source technologies as abbreviated in the diagram below -
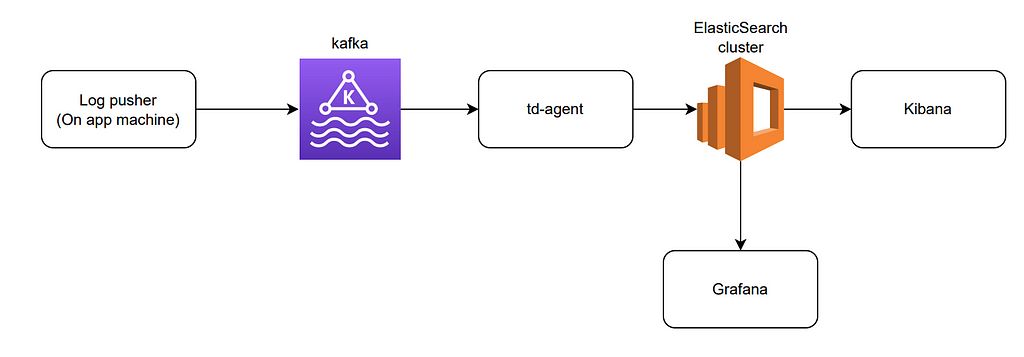
The overall pipeline consists of five major components —
- Log Pushers — Pushers, which are on the machines running the application, send logs to Kafka topics. We use Fluentbit and Filebeat agents as pushers on our EC2 instances and Kubernetes clusters. On EC2, pushers work as a separate process to send logs from the services on that machine. On Kubernetes, Fluentbit runs as a daemon to collect and send logs. We organize logs from different frameworks into different Kafka topics, allowing us to have better control over the processing scale based on the volume of logs generated.
- Intermediate Buffer — Holds the messages till they are processed by the aggregators. As we need a high throughput, scalable, fault-tolerant, and highly available system to push the log messages from the log pushers, Kafka becomes the evident choice.
- Log Aggregators — At this layer, log messages are analyzed, reformatted if necessary, and then pushed to the next layer. We use td-agent as aggregators in our pipeline.
- Storage — We store processed logs in an ElasticSearch cluster. The logs are rotated on a regular basis to optimize the storage needs.
- Presentation Layer — We have deployed Kiban and Grafana as the presentation layers over the log messages stored in the ElasticSearch cluster. These tools can be used to search the logs, plot graphs, see error rates, and set alerts.
Introduction of Kloudfuse — a comprehensive observability solution
After running the setup discussed above for several months, we decided to offload the last four components of our log pipeline (Intermediate Buffer, Log Aggregators, Storage, and Presentation Layer) to a comprehensive observability solution called Kloudfuse with the motive of having everything at one place and better control the cost.We’ll talk about how we replaced these components with Kloudfuse and how we made use of our previous work in this migration in an upcoming article.
Conclusion
In the pursuit of observability, 1mg’s story is a poignant reminder that logs aren’t just lines of text, they’re the threads that weave together a comprehensive understanding of the software landscape. As technology continues to advance and systems grow in complexity, the lessons from our experience offer a roadmap to achieving a clearer, more insightful picture of system behavior and performance.
Building a Clearer Picture: Rethinking Log Messages and Log Pipeline for Superior Observability at… was originally published in Tata 1mg Technology on Medium, where people are continuing the conversation by highlighting and responding to this story.
- Log in to post comments
- 4 views